데이터를 분석하거나 모델링하기 위한 초기 단계 중 하나는 변수가 어떻게 분포되어 있는지 이해하는 것입니다.
관측치들은 어떤 범위에 분포하나요? 그들의 중심 경향성은 무엇인가요? 한쪽 방향으로 매우 치우쳐져 있나요?
이중모드(bimodality)의 증거가 있나요? 유의한 이상치가 있나요?
이러한 질문에 대한 답은 다른 변수에 의해 정의된 하위 집합에서 달라질 수 있나요?
distributions module 에는 이러한 질문에 대답할 수 있는 여러 함수가 포함되어 있습니다.
축 레벨(ax-level) 함수는 histplot(), kdeplot(), ecdfplot(), rugplot()이 있습니다.
이러한 함수들은 figure-level displot(), jointplot(), pairplot() 함수 내에서 함께 그룹화됩니다.
분포를 시각화하기 위한 여러 가지 접근 방법이 있으며, 각각은 상대적인 장단점이 있습니다.
특정 목적에 가장 적합한 접근 방법을 선택할 수 있도록 이러한 요인을 이해하는 것이 중요합니다.
단변량 히스토그램 그리기
분포를 시각화하는 가장 일반적인 방법은 히스토그램입니다.
이것은 displot()에서 기본적인 접근 방법이며, 이 함수는 histplot()과 동일한 기본 코드를 사용합니다.
히스토그램은 데이터 변수를 나타내는 축을 일부 이산적인(bin)인 구간으로 분할하고 각 구간 내에 있는 관측치의 수를 해당 막대의 높이를 이용하여 표시하는 막대 그래프입니다.
sns.displot(penguins['flipper_length_mm'])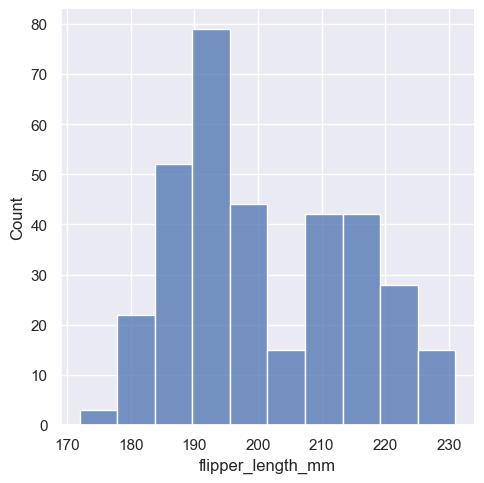
> 가장 일반적인 지느러미의 길이가 약 195cm 정도인 것을 볼 수 있습니다.
bin 값 고르기
빈(bin)의 크기는 중요한 매개변수이며,
잘못된 빈 크기를 사용하면 데이터의 중요한 특징을 가릴 수 있거나 무작위 가변성을 이용한 겉보기 특징을 만들어 낼 수 있습니다.
기본적으로 displot() 또는 histplot()는 데이터의 분산과 관측치 수에 기반하여 기본 빈 크기를 선택합니다.
서로 다른 빈 크기에서 분포의 인상이 일관되는지 확인하는 것이 좋습니다.
1 .binwidth
직접 크기를 선택하려면 binwidth 매개변수를 설정하면 됩니다.
sns.displot(penguins, x="flipper_length_mm", binwidth=5)
2. bins
다른 경우에는 빈(bin)의 크기 대신 빈의 수를 지정하는 것이 더 합리적일 수 있습니다.
이 경우, 빈의 크기는 데이터의 범위와 분산에 따라 자동으로 조정됩니다.
이 방법은 bins 매개변수에 정수 값을 할당하여 수동으로 지정할 수 있습니다.
sns.displot(penguins, x="flipper_length_mm", bins=20)

기본값(default)이 실패하는 경우 ( 1.bins / 2.discreat)
기본값(default)이 실패하는 경우의 예로는, 변수가 상대적으로 적은 수의 정수 값을 가지는 경우를 들 수 있습니다.
이 경우, 기본 bin 크기는 너무 작아서 분포를 제대로 표현하지 못할 수 있습니다.
tips = sns.load_dataset("tips")
sns.displot(tips, x="size")
이러한 경우, bins 매개변수에 배열(array)을 전달하여 정확한 빈 경계를 지정하는 방법이 있습니다.
또한 discrete=True로 설정하여 해결할 수 있습니다.
이 방법은 데이터셋 내 고유값(unique values)을 나타내는 빈 경계를 선택하고, 해당 값에 중심을 두어 막대를 만듭니다.
이 두가지 방법을 사용하면 위에서 언급한 문제를 해결할 수 있습니다.
1.sns.displot(tips, x="size", bins=[1, 2, 3, 4, 5, 6, 7])
2.sns.displot(tips, x="size", discrete=True)
범주형 변수 distplot
범주형 변수의 분포를 히스토그램의 논리로 시각화하는 것도 가능합니다.
범주형 변수에 대해서는 자동으로 이산적 빈(bin)이 설정되지만, 축의 범주 형태를 강조하기 위해 막대를 약간 축소하는 것(shrink)도 도움이 됩니다. 이러한 방법으로 범주형 변수의 분포를 시각화하면 해당 변수의 범주 간 비교와 총 범주 수에 대한 정보를 보다 직관적으로 파악할 수 있습니다.
sns.displot(tips, x="day", shrink=.8)
Conditioning on other variables (다른 변수에 대한 조건화)
변수에서의 분포를 이해한 후에는 종종 데이터 집합 내 다른 변수와의 차이를 파악하는 것이 다음 단계가 됩니다.
예를 들어, 앞서 본 flipper lengths 의 이중 모드 분포(bimodl distribution) 의 원인이 무엇인지 알아보려면 어떻게 해야할까요?
displot()과 histplot()은 hue 매개변수를 통해 조건부 서브셋(subset)을 지원합니다.
hue에 변수를 할당하면 해당 변수의 각 고유값마다 별도의 히스토그램을 그리고 색으로 구분합니다.
이 방법을 사용하면 데이터셋 내 다른 변수에 따른 분포의 차이를 그래프로 파악할 수 있습니다.
sns.displot(penguins, x="flipper_length_mm", hue="species")

step
기본적으로 서로 다른 히스토그램은 서로 겹쳐져(layered) 표시되며, 경우에 따라 구분하기 어려울 수 있습니다.
이 경우 히스토그램의 시각적 표현을 막대 그래프에서 "step" 그래프로 변경하는 것도 하나의 옵션입니다.
이 방법을 사용하면 각 히스토그램의 경계가 뚜렷하게 드러나기 때문에 서로 구분하기 쉬워집니다.
sns.displot(penguins, x="flipper_length_mm", hue="species", element="step")
stack
다른 대안으로, 각 막대를 겹치는 대신에 "stacked" 또는 수직으로 이동시켜 쌓는 것도 가능합니다.
이 그래프에서는 전체 히스토그램의 윤곽선이 동일한 하나의 변수로 만든 그래프와 일치합니다.
이 방식은 각 변수 간 상대적인 크기를 볼 수 있도록 하며, 경우에 따라 두 변수 간 상호작용(interaction)을 확인하는 데 유용할 수 있습니다.
sns.displot(penguins, x="flipper_length_mm", hue="species", multiple="stack")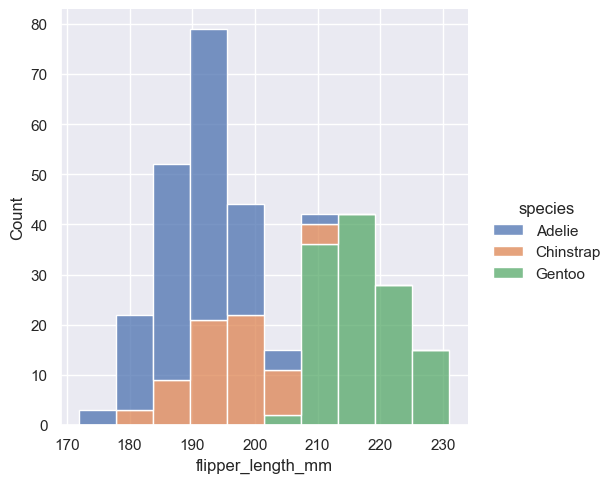
스택 집합 히스토그램은 변수 간의 부분-전체 관계를 강조하지만 (예를 들어, 어떤 종류의 Adelie 새의 분포 모드를 판별하는 것이 어려울 수 있습니다), 다른 특징을 가리기도 합니다.
dodge
또 다른 옵션은 막대를 "dodge"하는 방법으로, 막대를 수평으로 이동시켜 너비를 줄입니다.
이렇게 하면 막대들이 서로 겹치지 않도록하고, 높이를 기준으로 비교 가능하도록 보장합니다.
그러나 범주형 변수의 레벨 수가 적은 경우에만 잘 작동합니다.
sns.displot(penguins, x="flipper_length_mm", hue="sex", multiple="dodge")
col
displot() 함수는 Figure-Level 함수이며, FacetGrid에 그려지기 때문에,
hue 대신 col 또는 row에 두 번째 변수를 할당하여 각 개별 분포를 별도의 서브플롯에 그릴 수도 있습니다.
이 방식은 각 서브셋의 분포를 잘 나타내지만, 직접적인 비교를 그리기 어렵게 만들 수 있습니다.
즉, 서로 다른 subplot에서 분포를 비교하려면 subplot 간의 차이점을 고려해야합니다.
이 방법은 서로 다른 변수와 다른 feature를 한눈에 볼 수 있어, 데이터셋에서 특정 정보를 파악하기에 매우 유용합니다.
sns.displot(penguins, x="flipper_length_mm", col="sex")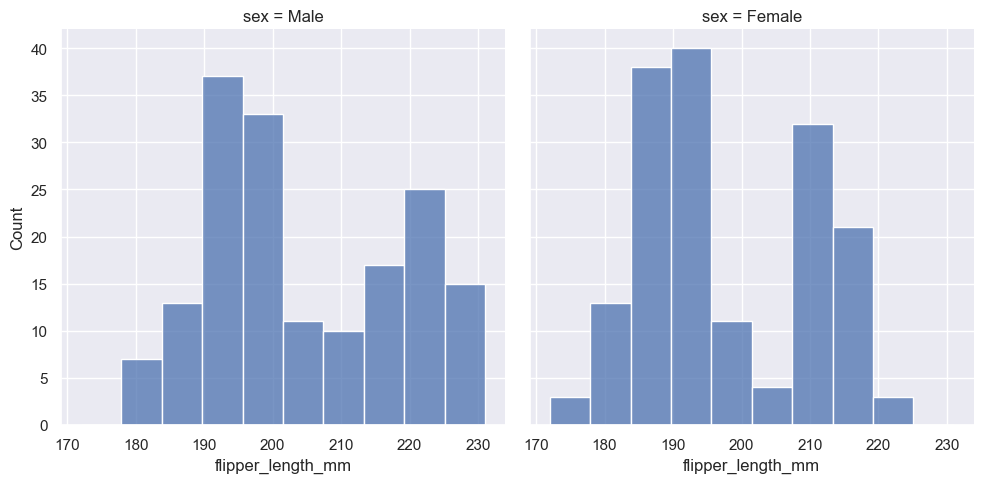
https://seaborn.pydata.org/tutorial/distributions.html#plotting-univariate-histograms
Visualizing distributions of data — seaborn 0.12.2 documentation
Visualizing distributions of data An early step in any effort to analyze or model data should be to understand how the variables are distributed. Techniques for distribution visualization can provide quick answers to many important questions. What range do
seaborn.pydata.org