자연어 처리란?
자연어 처리(Natural Language Processing, NLP)는 인간의 언어를 컴퓨터가 처리하도록 하는 인공지능의 한 분야입니다. NLP의 목표는 인간의 언어를 이해하고 생성할 수 있는 시스템을 개발하는 것입니다. 이를 통해 컴퓨터는 텍스트나 음성 데이터를 분석하고, 의미를 추출하며, 필요한 경우 자연어로 응답할 수 있게 됩니다. NLP는 기계 번역, 감정 분석, 챗봇 개발, 음성 인식 시스템 등 다양한 응용 분야에서 활용됩니다.
단어의 의미를 이해하고 처리하는 것은 NLP에서 중요한 과제 중 하나입니다.
단어의 의미를 이해하고 처리하는 방법으로는 세 가지가 있습니다.
- 시소러스를 활용한 기법
- 통계 기반 기법
- 추론 기반 기법(예: word2vec)
1. 시소러스 기반 기법
시소러스는 단어의 동의어, 반의어 등 의미적 관계를 포함하는 자료구조인데, 이를 행렬 형태로 표현한 것을 시소러스 행렬이라고 합니다. 이 행렬은 주로 단어 간의 의미적 유사성이나 관계를 수치화하여 나타내는 데 사용됩니다.
WordNet은 단어 간의 의미적 관계를 네트워크 형태로 구축한 대표적인 시소러스입니다. 동의어 그룹을 통해 단어들이 연결되어 있으며, 이를 통해 단어의 의미를 파악하고, 유사도를 측정하는 데 사용됩니다.
시소러스의 문제점
시소러스 행렬의 문제점 중 하나는 그것이 정적이라는 것입니다. 즉, 언어의 사용이나 의미가 시간에 따라 변할 때 이를 반영하기 위해서는 행렬을 수동으로 업데이트해야 합니다. 또한, 모든 단어의 의미적 관계를 완벽하게 포착하는 것은 매우 어렵기 때문에, 이 행렬은 항상 어느 정도의 근사치만을 제공할 수 있습니다.
2. 통계 기반 기법
통계 기반 기법은 '분포 가설'에 기반을 두고 있습니다.
분포 가설
분포 가설은 "단어의 의미는 그 단어가 사용된 문맥으로부터 유추할 수 있다"는 아이디어를 기반으로 합니다. 즉, 비슷한 문맥에서 사용되는 단어들은 비슷한 의미를 가진다고 볼 수 있습니다. 이 가설에 따라, 단어의 의미는 단독으로 존재하는 것이 아니라, 그 단어가 등장하는 주변 단어들과의 관계 속에서 형성됩니다.
예를 들어, "The cat sat on the mat"와 "A dog lay on the rug"라는 문장을 살펴보겠습니다. 여기에서 "mat"과 "rug"는 서로 다른 단어지만, 둘 다 '작은 카펫' 또는 '바닥에 깔기 위한 직물 제품'이라는 비슷한 개념을 나타냅니다. 이 두 단어가 비슷한 문맥에서 사용됨으로써, 우리는 두 단어가 비슷한 의미를 가진다는 것을 유추할 수 있습니다. 즉, '바닥에 깔아서 사용하는 것'이라는 공통된 맥락을 공유하고 있기 때문에, "mat"과 "rug"는 의미적으로 관련이 있음을 알 수 있습니다.
이러한 문맥적 유사성을 통해, 두 단어가 의미적으로 서로 관련이 있음을 유추할 수 있습니다.
말뭉치의 역할
통계 기반 기법을 적용하기 위해서는 대량의 텍스트 데이터, 즉 '말뭉치(corpus)'가 필요합니다. 말뭉치는 특정 언어나 주제, 스타일 등을 대표하는 텍스트 모음으로, 자연어 처리 시스템이 학습할 수 있는 데이터의 원천입니다. 이러한 말뭉치는 신문 기사, 책, 웹 페이지, 소셜 미디어 포스트 등 다양한 출처에서 수집될 수 있습니다.
2.1 동시 발생 행렬(Co-occurrence Matrix)
동시 발생 행렬(Co-occurrence Matrix)은 단어 간의 관계를 수량화하기 위해 사용되는 중요한 통계 기반 기법입니다. 이 행렬은 단어들이 문맥 내에서 얼마나 자주 함께 나타나는지를 나타내며, 이를 통해 단어 간의 의미적 관계를 파악할 수 있습니다.
동시 발생 행렬의 구조
동시 발생 행렬은 보통 2차원 배열 형태로 표현되며, 배열의 행과 열은 말뭉치(corpus) 내의 고유한 단어들로 구성됩니다. 행렬의 각 셀은 두 단어가 특정 문맥 내에서 함께 발생한 횟수를 나타냅니다. 문맥의 크기는 "윈도우(window)"라고 불리며, 주변 단어를 얼마나 멀리까지 고려할 것인지를 결정합니다.
예를 들어 "You say goodbye and I say hello."라는 문장이 있고, 윈도우 크기를 1로 설정했을 때 you 단어의 동시 발생 행렬의 빈도는 아래 첨부한 이미지와 같습니다. 이 경우 you의 한 칸 오른쪽 옆에 say가 있기 때문에 동시 발생 행렬에서 you 행의 say 열에 1이 기록되고, 나머지는 0으로 기록됩니다.

그럼 만약 윈도우 크기를 2로 설정했을 때 and 단어의 동시 발생 행렬의 빈도는 어떨까요?
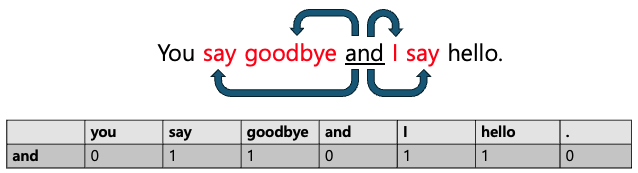
이 경우 and의 한 칸 왼쪽 옆에 goodbye, 두 칸 왼쪽 옆에 say 그리고 한 칸 오른쪽 옆에 I, 두 칸 오른쪽 옆에 say 가 있기 때문에 동시 발생 행렬에서 and 행의 say, goodbye, I, hello 열에 1이 기록되고, 나머지는 0으로 기록됩니다.
위와 같이 어떤 단어에 주목했을 때, 그 주변에 어떤 단어가 몇 번이나 등장하는지를 세어 집계하는 방법을 통계 기반 기법이라고 합니다.
동시 발생 행렬의 생성
동시 발생 행렬을 생성하는 과정은 다음과 같습니다.
1. 말뭉치 선택: 분석할 텍스트 데이터를 선택합니다.
2. 토큰화: 텍스트를 개별 단어(토큰)로 분리합니다.
3. 윈도우 크기 설정: 단어 간의 관계를 파악하기 위해 고려할 문맥의 크기(윈도우 크기)를 결정합니다.
4. 동시 발생 행렬 계산: 각 단어 쌍에 대해, 설정된 창 크기 내에서 함께 나타나는 횟수를 계산하여 행렬에 기록합니다.
위에서 했던 작업을 모든 단어(7개 단어)에 대해서 수행한 결과는 아래와 같습니다. (윈도우 크기:1)

2.2 벡터 간 유사도 (코사인 유사도)
벡터로 작업할 때 주요 질문 중 하나는 "이 두 벡터는 얼마나 유사합니까?"입니다. 코사인 유사도는 다차원 공간에서 두 벡터 사이의 각도의 코사인을 평가하므로 이러한 측면을 측정하는 데 사용되는 측정항목입니다. 이는 서로에 대한 두 벡터의 방향을 효과적으로 알려줍니다.

코사인 유사도는 크기가 아니라 방향을 측정하기 때문에 특히 유용합니다. 0도 각도에 있는 두 벡터의 코사인 유사도는 1로, 이는 두 벡터가 정확히 같은 방향을 가리키고 있음을 나타냅니다. 반대로, 두 벡터가 서로 180도이면 코사인 유사도는 -1이며 이는 정반대임을 나타냅니다.
벡터의 크기를 고려하지 않고 방향만 고려하는 이 특성은 단어 수 또는 용어 빈도 형태의 텍스트 데이터를 처리할 때 특히 유용합니다. 문서의 길이는 크게 다를 수 있지만 용어 빈도 벡터의 방향은 유사성을 더 잘 나타냅니다.
예를 들어, 텍스트 분석 및 자연어 처리에서 코사인 유사성은 두 문서의 내용이 얼마나 유사한지 평가하는 데 사용됩니다. 이는 문서를 용어 빈도의 벡터(종종 문서 전체에서 용어가 얼마나 고유한지에 따라 개수를 조정하는 TF-IDF 형식)로 표현한 다음 이러한 벡터 사이의 각도의 코사인을 계산함으로써 수행됩니다.
또한 코사인 유사성은 가장 가까운 일치 항목을 찾거나 유사한 항목을 그룹화하려는 경우 분류 또는 클러스터링을 위한 k-최근접 이웃과 같은 기계 학습 알고리즘에서 중요한 역할을 합니다.
요약하자면, 코사인 유사성은 크기와 무관하고 순전히 방향성에 초점을 맞춘 유사성 척도를 제공합니다.
정리하자면,
동시 발생 행렬은 특정 사건이나 개체가 함께 나타나는 빈도를 나타냅니다. NLP의 맥락에서 이는 주어진 텍스트 모음 내의 단어나 구와 관련된 경우가 많습니다. 결과 행렬은 단어 간의 연관성과 의미론적 유사성을 추론하는 데 사용할 수 있는 문맥에서 단어가 어떻게 공존하는지를 반영하는 통계적 표현입니다.
반면에 코사인 유사성은 0이 아닌 두 벡터 사이의 각도의 코사인을 계산하는 두 벡터 사이의 유사성을 측정한 것입니다. 이 측정항목은 발생 횟수 또는 빈도(예: 문서의 단어 수)에서 파생되는 벡터의 내적 및 크기를 기반으로 하기 때문에 통계적 척도입니다. 일반적으로 텍스트 분석의 문서나 추천 시스템의 항목을 비교하는 데 사용됩니다.
두 방법 모두 통계 정보, 즉 결합 발생 통계에 대한 동시 발생 행렬과 벡터 표현 간의 각도 통계에 대한 코사인 유사성에 의존합니다. 이는 클러스터링, 분류 및 정보 검색 작업에 사용되는 많은 알고리즘의 기초입니다.
다음 글
동시발생 행렬의 한계와 해결책(feat. PPMI)
동시발생행렬은 말뭉치(corpus) 내에서 일정한 맥락 안에서 각 단어 쌍이 함께 등장하는 횟수를 세는 표입니다. 언어학, 자연어 처리, 데이터 분석에서 관계와 패턴을 분석하는데 유용한 도구지만
resultofeffort.tistory.com
'밑바닥 DL' 카테고리의 다른 글
| [밑바닥 DL] 4.word2vec와 추론 기반 기법 (feat.CBOW와 Skip-gram 모델로 단어 학습) (1) | 2024.05.01 |
|---|---|
| [밑바닥 DL] 3.PPMI의 한계와 차원 감소(feat.SVD) (0) | 2024.04.05 |
| [밑바닥 DL] 2.동시발생 행렬의 한계와 해결책(feat. PPMI) (0) | 2024.03.14 |