정규 표현식(Regular Expression)
정규 표현식은 텍스트 전처리에서 유용한 도구로, 특정 규칙에 따라 문자열을 검색하고 조작할 수 있는 패턴 매칭 기술입니다.
파이썬에서는 re 모듈을 통해 정규 표현식을 지원하며, 이를 사용하여 텍스트 데이터를 신속하게 정제하고 처리할 수 있습니다. 이번 포스팅에서는 정규 표현식의 문법, 주요 함수 및 실습 예제를 살펴보겠습니다.
정규 표현식(Regular Expression) 실습
정규 표현식의 특수 문자(metacharacters)

. 기호
. 기호는 한 개의 임의의 문자를 나타냅니다.(줄 바꿈 문자 제외)
따라서 패턴 "p.n"은 'p'로 시작하고, 그다음에 임의의 한 글자가 오며, 'n'으로 끝나는 문자열과 일치합니다.
import re
re = re.compile("p.n")
# 이 문자열은 'p'로 시작하고 중간에 임의의 문자 'a'가 있으며 'n'으로 끝나므로 패턴과 일치합니다.
print(re.search("pan"))
# 이 문자열은 'p'와 'n' 사이에 두 글자 ('io')가 있어 패턴과 일치하지 않습니다.
print(re.search("pion"))
# 이 문자열은 'p'로 시작하지 않으므로 패턴과 일치하지 않습니다.
print(re.search("car"))
-------------출력---------------
<re.Match object; span=(0, 3), match='pan'>
None
None
? 기호
? 기호는 바로 앞에 있는 문자가 0개 또는 1개 존재할 수 있음을 나타냅니다.
따라서 패턴 "ab?c"는 'a'로 시작하고, 그다음에 'b'가 0개 또는 1개 올 수 있으며, 마지막에 'c'로 끝나는 문자열과 일치합니다.
import re
# 패턴 "ab?c"를 컴파일하여 r에 저장합니다.
r = re.compile("ab?c")
# 문자열 "abc"는 'a'와 'c' 사이에 'b'가 하나 있어 패턴과 일치합니다.
print(r.search("abc"))
# 문자열 "ac"는 'a'와 'c' 사이에 'b'가 없어도 패턴과 일치합니다.
print(r.search("ac"))
# 문자열 "abbc"는 'a'와 'c' 사이에 'b'가 두 개 있으므로 패턴과 일치하지 않습니다.
print(r.search("abbc"))
# 문자열 "aXc"는 'a'와 'c' 사이에 'b'가 아닌 다른 문자가 있으므로 패턴과 일치하지 않습니다.
print(r.search("aXc"))
# -------------출력---------------
# <re.Match object; span=(0, 3), match='abc'>
# <re.Match object; span=(0, 2), match='ac'>
# None
# None
* 기호
* 기호는 바로 앞에 있는 문자가 0개 이상 있을 수 있음을 나타냅니다.
따라서 패턴 "ab*c"는 'a'로 시작하고, 그다음에 'b'가 0개 이상 올 수 있으며, 마지막에 'c'로 끝나는 문자열과 일치합니다.
import re
# 패턴 "ab*c"를 컴파일하여 r에 저장합니다.
r = re.compile("ab*c")
# 문자열 "ac"는 'a'와 'c' 사이에 'b'가 없으므로 패턴과 일치합니다.
print(r.search("ac"))
# 문자열 "abbc"는 'a'와 'c' 사이에 'b'가 두 개 있으므로 패턴과 일치합니다.
print(r.search("abbc"))
# 문자열 "aXc"는 'a'와 'c' 사이에 'b'가 아닌 다른 문자가 있으므로 패턴과 일치하지 않습니다.
print(r.search("aXc"))
# -------------출력---------------
# <re.Match object; span=(0, 2), match='ac'>
# <re.Match object; span=(0, 4), match='abbc'>
# None+ 기호
+ 기호는 바로 앞에 있는 문자가 1개 이상 있어야 함을 나타냅니다.
따라서 패턴 "ab+c"는 'a'로 시작하고, 그 다음에 'b'가 1개 이상 있어야 하며, 마지막에 'c'로 끝나는 문자열과 일치합니다.
import re
# 패턴 "ab+c"를 컴파일하여 r에 저장합니다.
r = re.compile("ab+c")
# 문자열 "ac"는 'a'와 'c' 사이에 'b'가 없으므로 패턴과 일치하지 않습니다.
print(r.search("ac"))
# 문자열 "abc"는 'a'와 'c' 사이에 'b'가 하나 있으므로 패턴과 일치합니다.
print(r.search("abc"))
# 문자열 "aXc"는 'a'와 'c' 사이에 'b'가 아니라 'X'가 있으므로 패턴과 일치하지 않습니다.
print(r.search("aXc"))
# -------------출력---------------
# None
# <re.Match object; span=(0, 3), match='abc'>
# None
^ 기호
^ 기호는 문자열의 시작 부분을 나타냅니다.
따라서 패턴 "^hello"는 문자열이 "hello"로 시작할 때만 일치합니다.
import re
# 패턴 "^hello"를 컴파일하여 r에 저장합니다.
r = re.compile("^hello")
print(r.search("hello world")) # 문자열이 "hello"로 시작하므로 매치
print(r.search("hello")) # 문자열이 "hello"로 시작하므로 매치
print(r.search("hellooo")) # 문자열이 "hello"로 시작하므로 매치
print(r.search("world hello")) # 문자열이 "hello"로 시작하지 않으므로 매치되지 않음
print(r.search("hi there")) # 문자열이 "hello"로 시작하지 않으므로 매치되지 않음
# -------------출력---------------
# <re.Match object; span=(0, 5), match='hello'>
# <re.Match object; span=(0, 5), match='hello'>
# <re.Match object; span=(0, 5), match='hello'>
# None
# None
$ 기호
$ 기호는 문자열의 끝 부분을 나타냅니다.
따라서 패턴 "end$"는 문자열이 "end"로 끝날 때만 일치합니다.
import re
# 패턴 "end$"를 컴파일하여 r에 저장합니다.
r = re.compile("end$")
print(r.search("the end")) # 문자열이 "end"로 끝나므로 매치
print(r.search("end")) # 문자열이 "end"로 끝나므로 매치
print(r.search("ending")) # 문자열이 "end"로 끝나지 않으므로 매치되지 않음
print(r.search("the end of it")) # 문자열이 "end"로 끝나지 않으므로 매치되지 않음
print(r.search("this is the end")) # 문자열이 "end"로 끝나므로 매치
# -------------예상 출력---------------
# <re.Match object; span=(4, 7), match='end'>
# <re.Match object; span=(0, 3), match='end'>
# None
# None
# <re.Match object; span=(12, 15), match='end'>
{숫자} 기호
{숫자} 기호는 바로 앞에 있는 문자가 지정된 횟수만큼 연속으로 나타나야 함을 의미합니다.
따라서 패턴 "a{3}"는 'a'가 정확히 3번 연속으로 나타날 때만 일치합니다.
import re
# 패턴 "a{3}"를 컴파일하여 r에 저장합니다.
r = re.compile("a{3}")
# 문자열 "aaa"는 'a'가 3개 연속으로 있어 패턴과 일치합니다.
print(r.search("aaa"))
# 문자열 "aa"는 'a'가 2개뿐이므로 패턴과 일치하지 않습니다.
print(r.search("aa"))
# 문자열 "aaaa"는 'a'가 4개 연속이지만, 첫 번째 3개가 패턴과 일치합니다.
print(r.search("aaaa"))
# 문자열 "a"는 'a'가 1개뿐이므로 패턴과 일치하지 않습니다.
print(r.search("a"))
# 문자열 "aabaa"는 연속된 'a'가 2개뿐이므로 패턴과 일치하지 않습니다.
print(r.search("aabaa"))
# 문자열 "bcadaaa"는 'a'가 3개 연속으로 나타나는 부분이 있어 패턴과 일치합니다.
print(r.search("bcadaaa"))
# -------------예상 출력---------------
# <re.Match object; span=(0, 3), match='aaa'>
# None
# <re.Match object; span=(0, 3), match='aaa'>
# None
# None
# <re.Match object; span=(4, 7), match='aaa'>
{숫자1, 숫자2} 기호
{숫자1, 숫자2} 기호는 바로 앞에 있는 문자가 최소 숫자 1번, 최대 숫자 2번까지 연속으로 나타날 수 있음을 의미합니다.
따라서 패턴 "a{2,4}"는 'a'가 최소 2번에서 최대 4번까지 연속으로 나타날 때 일치합니다.
import re
# 패턴 "a{2,4}"를 컴파일하여 r에 저장합니다.
r = re.compile("a{2,4}")
# 문자열 "aa"는 'a'가 2개 연속으로 있어 패턴과 일치합니다.
print(r.search("aa"))
# 문자열 "aaaa"는 'a'가 4개 연속으로 있어 패턴과 일치합니다.
print(r.search("aaaa"))
# 문자열 "aaaaa"는 'a'가 5개 연속으로 있지만, 패턴은 최대 4개까지만 허용하므로 첫 4개의 'a'만 매치됩니다.
print(r.search("aaaaa"))
# 문자열 "a"는 'a'가 1개뿐이므로 패턴과 일치하지 않습니다.
print(r.search("a"))
# 문자열 "baaac"는 'a'가 연속으로 3개 있어 패턴과 일치합니다.
print(r.search("baaac"))
# -------------출력---------------
# <re.Match object; span=(0, 2), match='aa'>
# <re.Match object; span=(0, 4), match='aaaa'>
# <re.Match object; span=(0, 4), match='aaaa'>
# None
# <re.Match object; span=(1, 4), match='aaa'>
{숫자, } 기호
{숫자, } 기호는 바로 앞에 있는 문자가 최소 숫자 번 이상 연속으로 나타나야 함을 의미합니다.
따라서 패턴 "a{2,}"는 'a'가 최소 2번 이상 연속으로 나타날 때 일치합니다.
import re
# 패턴 "a{2,}"를 컴파일하여 r에 저장합니다.
r = re.compile("a{2,}")
# 문자열 "aa"는 'a'가 2개 연속으로 있어 패턴과 일치합니다.
print(r.search("aa")) # 'a'가 2개 있으므로 매치
# 문자열 "aaaa"는 'a'가 4개 연속으로 있어 패턴과 일치합니다.
print(r.search("aaaa")) # 'a'가 4개 있으므로 매치
# 문자열 "a"는 'a'가 1개뿐이므로 패턴과 일치하지 않습니다.
print(r.search("a")) # 'a'가 1개 있으므로 매치되지 않음
# 문자열 "bbaaa"는 'a'가 3개 연속으로 나타나는 부분이 있어 패턴과 일치합니다.
print(r.search("bbaaa")) # 'a'가 3개 있으므로 매치
# 문자열 "bb"는 'a'가 없으므로 패턴과 일치하지 않습니다.
print(r.search("bb")) # 'a'가 없으므로 매치되지 않음
# -------------출력---------------
# <re.Match object; span=(0, 2), match='aa'>
# <re.Match object; span=(0, 4), match='aaaa'>
# None
# <re.Match object; span=(2, 5), match='aaa'>
# None
[] 기호
[] 기호는 대괄호 안에 있는 문자들 중 하나와 일치하는 경우를 찾습니다.
"[abc]"는 'a', 'b', 또는 'c' 중 하나의 문자와 매치됩니다.
import re
# 패턴 "[abc]"를 컴파일하여 r에 저장합니다.
r = re.compile("[abc]")
# 문자열 "apple"에는 'a'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("apple"))
# 문자열 "banana"에는 'b'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("banana"))
# 문자열 "cherry"에는 'c'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("cherry"))
# 문자열 "kiwi"에는 'a', 'b', 'c' 중 어느 것도 포함되어 있지 않으므로 패턴과 일치하지 않습니다.
print(r.search("kiwi"))
# -------------출력---------------
# <re.Match object; span=(0, 1), match='a'>
# <re.Match object; span=(0, 1), match='b'>
# <re.Match object; span=(0, 1), match='c'>
# None
# None
"[a-z]"와 같이 사용하면 소문자 알파벳 전체(a부터 z까지) 중 하나의 문자와 매치됩니다.
import re
# 'a', 'b', 또는 'c' 중 하나의 문자와 매치됩니다.
r = re.compile("[a-z]")
print(r.search("apple")) # 'a'가 있으므로 매치
print(r.search("banana")) # 'b'가 있으므로 매치
print(r.search("cherry")) # 'c'가 있으므로 매치
# -------------출력---------------
# <re.Match object; span=(0, 1), match='a'>
# <re.Match object; span=(0, 1), match='b'>
# <re.Match object; span=(0, 1), match='c'>[^문자] 기호
[^문자] 기호는 대괄호 안에 있는 문자들을 제외한 나머지 문자와 일치합니다.
예를 들어, "[^abc]"는 'a', 'b', 'c'가 아닌 모든 문자와 매치됩니다.
import re
# 패턴 "[^abc]"를 컴파일하여 r에 저장합니다.
r = re.compile("[^abc]")
# 문자열 "apple"에는 'a', 'b', 'c'가 아닌 문자 'p'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("apple"))
# 문자열 "banana"에는 'a', 'b', 'c'가 아닌 문자 'n'이 포함되어 있으므로 패턴과 일치합니다.
print(r.search("banana"))
# 문자열 "cherry"에는 'a', 'b', 'c'가 아닌 문자 'h'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("cherry"))
# 문자열 "abc"에는 'a', 'b', 'c'로만 이루어져 있으므로 패턴과 일치하지 않습니다.
print(r.search("abc"))
# 문자열 "A"에는 'a', 'b', 'c'가 아닌 대문자 'A'가 포함되어 있으므로 패턴과 일치합니다.
print(r.search("A"))
# 문자열 "b"는 'a', 'b', 'c' 중 하나로만 이루어져 있으므로 패턴과 일치하지 않습니다.
print(r.search("b"))
# -------------예상 출력---------------
# <re.Match object; span=(1, 2), match='p'>
# <re.Match object; span=(2, 3), match='n'>
# <re.Match object; span=(1, 2), match='h'>
# None
# <re.Match object; span=(0, 1), match='A'>
# None
정규 표현식(regular expression) 모듈 함수

match 함수
match 함수는 문자열의 시작 부분이 패턴과 일치하는지 확인합니다.
즉, 문자열의 첫 번째 문자가 패턴과 일치해야 매치됩니다.
import re
# 패턴 "[^abc]"를 컴파일하여 r에 저장합니다.
r = re.compile("[^abc]")
# 문자열 "apple"은 'a'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("apple"))
# 문자열 "banana"는 'b'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("banana"))
# 문자열 "cherry"는 'c'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("cherry"))
# 문자열 "abc"는 'a'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("abc"))
# 문자열 "A"는 대문자 'A'로 시작하며, 'a', 'b', 'c'가 아니므로 패턴과 일치합니다.
print(r.match("A"))
# 문자열 "b"는 'b'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("b"))
# 문자열 "C"는 대문자 'C'로 시작하므로 패턴과 일치하지 않습니다.
print(r.match("C"))
# -------------예상 출력---------------
# None
# None
# None
# None
# <re.Match object; span=(0, 1), match='A'>
# None
# Nonesplit 함수
split 함수는 지정된 패턴을 기준으로 문자열을 분리하여 리스트로 반환합니다.
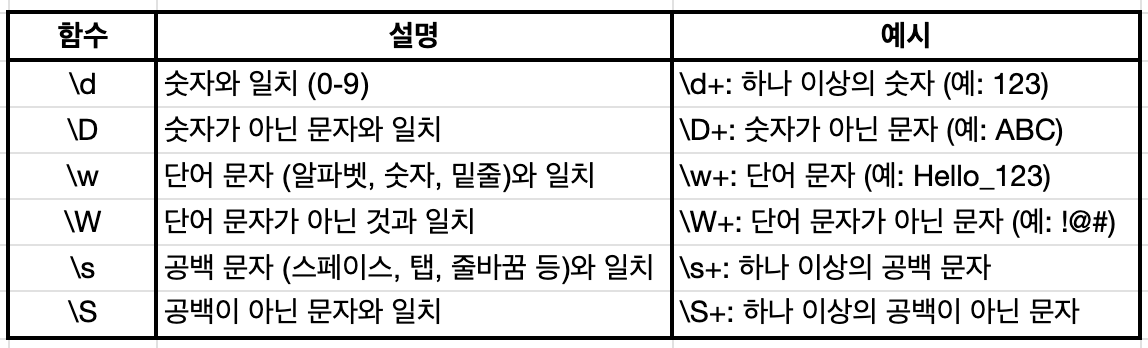
"\s+": 하나 이상의 공백(띄어쓰기, 탭, 줄 바꿈 등)을 기준으로 문자열을 분리합니다.
- \s는 공백 문자(띄어쓰기, 탭, 줄 바꿈 등)를 의미하고,
- +는 그 문자가 하나 이상 연속으로 나올 때를 뜻합니다.
import re
text1 = "사과 딸기 수박 메론 바나나"
result1 = re.split(r"\s+", text1) # 공백 기준으로 분리
print("공백 기준 분리:", result1)
> 공백 기준 분리: ['사과', '딸기', '수박', '메론', '바나나']
"\n" : 줄 바꿈을 기준으로 문자열을 분리합니다.
text2 = """사과
딸기
수박
메론
바나나"""
result2 = re.split(r"\n", text2) # 줄바꿈 기준으로 분리
print("줄바꿈 기준 분리:", result2)
> 줄바꿈 기준 분리: ['사과', '딸기', '수박', '메론', '바나나']
"\+": + 를 기준으로 문자열을 분리합니다.
text3 = "사과+딸기+수박+메론+바나나"
result3 = re.split(r"\+", text3) # '+' 기준으로 분리
print("더하기 기호 기준 분리:", result3)
> 더하기 기호 기준 분리: ['사과', '딸기', '수박', '메론', '바나나']
"공백, 줄 바꿈, +"를 기준으로 문자열을 분리합니다.
text4 = "사과+딸기 수박\n메론 바나나"
result4 = re.split(r"[+\s\n]+", text4) # 공백, 줄바꿈, '+' 기준으로 분리
print("여러 구분자 기준 분리:", result4)
> 여러 구분자 기준 분리: ['사과', '딸기', '수박', '메론', '바나나']findall 함수
findall 함수는 지정된 패턴과 일치하는 모든 문자열을 찾아 리스트로 반환합니다.
숫자를 찾는 정규 표현식
text1 = """이름: 김철수
전화번호: 010-1234-5678
나이: 30세
성별: 남자"""
# 숫자를 모두 찾아서 리스트로 반환합니다.
numbers = re.findall(r'\d+', text1) # \d+는 하나 이상의 숫자를 의미
print("찾은 숫자들:", numbers)
> 찾은 숫자들: ['010', '1234', '5678', '30']
이메일 주소를 찾는 정규 표현식
text2 = "제 이메일은 example@example.com입니다. 그리고 다른 이메일은 test123@gmail.com입니다."
# 이메일 주소를 모두 찾아서 리스트로 반환합니다.
emails = re.findall(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}', text2)
print("찾은 이메일 주소들:", emails)
> 찾은 이메일 주소들: ['example@example.com', 'test123@gmail.com']
특정 단어를 찾는 정규 표현식
text3 = "사과, 딸기, 수박, 메론, 바나나가 있습니다."
# '사과'라는 단어를 모두 찾아서 리스트로 반환합니다.
fruits = re.findall(r'사과', text3)
print("찾은 단어들:", fruits)
> 찾은 단어들: ['사과']
대문자 알파벳을 찾는 정규 표현식
# 대문자 알파벳을 찾는 정규 표현식
text4 = "ABCdefGHIjklMNO"
# 대문자 알파벳을 모두 찾아서 리스트로 반환합니다.
uppercase_letters = re.findall(r'[A-Z]', text4)
print("찾은 대문자 알파벳:", uppercase_letters)
> 찾은 대문자 알파벳: ['A', 'B', 'C', 'G', 'H', 'I', 'M', 'N', 'O']sub 함수
sub 함수는 지정된 패턴과 일치하는 부분을 다른 문자열로 대체합니다.
첫 번째 매개변수는 대체할 문자열, 두 번째 매개변수는 대상 문자열입니다.
문자열에서 모든 숫자를 제거
text1 = "전화번호: 010-1234-5678, 나이: 30세"
# 모든 숫자를 공백으로 대체합니다.
result1 = re.sub(r'\d+', '', text1)
print("숫자 제거:", result1)
> 숫자 제거: 전화번호: --, 나이: 세
특정 단어를 다른 단어로 대체
text2 = "사과, 딸기, 수박, 사과가 있습니다."
# '사과'를 '포도'로 대체합니다.
result2 = re.sub(r'사과', '포도', text2)
print("단어 대체:", result2)
> 단어 대체: 포도, 딸기, 수박, 포도가 있습니다.
특수 문자를 제거
text3 = "안녕하세요! 여기는 Python@OpenAI입니다."
# 특수 문자를 공백으로 대체합니다.
result3 = re.sub(r'[^a-zA-Z0-9가-힣\s]', ' ', text3)
print("특수 문자 제거:", result3)
> 특수 문자 제거: 안녕하세요 여기는 Python OpenAI입니다
다중 공백을 하나의 공백으로 대체
text4 = "사과 딸기 수박 메론 바나나"
# 다중 공백을 하나의 공백으로 대체합니다.
result4 = re.sub(r'\s+', ' ', text4)
print("다중 공백 제거:", result4)
> 다중 공백 제거: 사과 딸기 수박 메론 바나나정규 표현식을 이용한 토큰화 (RegexpTokenizer)
`RegexpTokenizer`는 `nltk.tokenize` 모듈의 클래스 중 하나로,
사용자가 지정한 정규 표현식(regular expression, regex)을 기준으로 텍스트를 토큰화하는 도구입니다.
일반적인 단어 분리 방식이 아닌, 특정 패턴에 따라 유연하게 텍스트를 분리하거나 원하는 요소만 추출할 수 있도록 해줍니다.
`RegexpTokenizer`의 주요 기능
- 패턴 기반 토큰화
`RegexpTokenizer`는 특정 패턴을 입력받아, 그 패턴과 일치하는 부분을 토큰으로 추출하거나(기본 설정), 그 패턴을 기준으로 텍스트를 나누는 기능을 수행합니다.
- 정규 표현식 사용
일반적인 공백, 구두점 등을 기반으로 하지 않고, 정규 표현식을 사용해 더 복잡하고 유연한 조건을 적용할 수 있습니다.
- gaps 옵션
`gaps=True`로 설정하면 패턴에 해당하는 부분을 기준으로 텍스트를 분리하고,
`gaps=False`로 설정하면 일치하는 부분 자체를 토큰으로 추출합니다.
`RegexpTokenizer`의 사용법
from nltk.tokenize import RegexpTokenizer
# 예제 텍스트
text = "Hello there! How's everything going? Call me at 123-456-7890."
# 문자와 아포스트로피 포함된 단어를 추출하는 토크나이저
tokenizer1 = RegexpTokenizer(r"[\w']+")
print("단어 토큰화 결과:", tokenizer1.tokenize(text))
# 공백을 기준으로 텍스트를 나누는 토크나이저 (공백을 제외하고 모든 텍스트를 토큰으로 반환)
tokenizer2 = RegexpTokenizer(r"\s+", gaps=True)
print("공백 기준 분리 결과:", tokenizer2.tokenize(text))
# 구두점과 숫자만 추출하는 토크나이저
tokenizer3 = RegexpTokenizer(r"[,.!?0-9]+")
print("구두점 및 숫자 추출 결과:", tokenizer3.tokenize(text))
-----------출력-----------
단어 토큰화 결과: ['Hello', 'there', "How's", 'everything', 'going', 'Call', 'me', 'at', '123', '456', '7890']
공백 기준 분리 결과: ['Hello', 'there!', "How's", 'everything', 'going?', 'Call', 'me', 'at', '123-456-7890.']
구두점 및 숫자 추출 결과: ['!', '?', '123', '456', '7890.']
- `tokenizer1`은 단어(`\w`)와 아포스트로피(`'`)가 포함된 토큰을 추출합니다.
- `tokenizer2`는 공백(`\s+`)을 기준으로 텍스트를 분리하는데, `gaps=True`로 설정되어 공백을 제외한 모든 텍스트가 토큰으로 반환됩니다.
- `tokenizer3`는 `, . ! ?` 등의 구두점이나 숫자(`0-9`)에 해당하는 패턴을 토큰으로 추출합니다.
'pytorch' 카테고리의 다른 글
| [pytorch] Bag of Words (BOW) | CountVectorizer (0) | 2024.11.19 |
|---|---|
| [pytorch] 정수 인코딩(Integer Encoding) | Counter 와 FreqDist를 활용한 정수 인코딩 코드 (2) | 2024.11.14 |
| [pytorch] 어간 추출(stemming)과 표제어 추출 (Lemmatization) (3) | 2024.11.12 |
| [pytorch] 불용어(stopwords)란? | 한국어 불용어 제거 | 영어 불용어 제거 (2) | 2024.11.04 |
| [pytorch] 토큰화 | 토크나이저(Tokenization) (4) | 2024.10.31 |