전이 학습(transfer learning)이란?
하나의 문제를 해결하기 위해 학습된 모델의 지식을 다른 문제를 해결하는데 활용하는 기법입니다.
즉, 기존에 학습한 모델의 가중치와 편향값 등의 정보를 새로운 모델의 초기값으로 활용하여 학습을 진행하는 것을 의미합니다.
전이 학습은 대규모 데이터셋을 가지고 모델을 학습시키는데 필요한 시간과 비용을 줄일 수 있습니다.
또한, 새로운 데이터셋에 대한 모델의 정확도를 높일 수 있습니다.
이는 기존 모델에서 학습한 특성이 비슷한 문제에서도 유용하기 때문입니다.
전이 학습은 크게 두 가지 방법으로 나뉩니다.
- 특성 추출(Feature Extraction): 사전 학습된 모델을 사용하여 새로운 모델을 초기화하는 방법
→ 전체 모델을 처음부터 학습시키는 것보다 효율적 - 미세 조정기법(fine-tuning): 사전 학습된 모델의 일부를 재사용하여 새로운 모델을 구성하는 방법
→ 새로운 문제에 더 맞는 모델을 구성할 수 있음

특성 추출 기법
사전 학습된 모델을 사용하여 새로운 데이터셋에서 특성을 추출하는 기법입니다.
특성 추출 기법은 사전 학습된 모델에서 이미지 데이터를 입력으로 받아서 합성곱층(convolutional layer)을 통해 이미지의 특성을 추출합니다. 이렇게 추출된 특성은 최종적으로 완전 연결층(fully connected layer)을 통해 분류됩니다.
새로운 데이터셋에서 특성 추출을 위해서는, 먼저 사전 학습된 모델의 합성곱층을 고정(freeze)시키고, 완전 연결층 부분만 새로운 데이터셋에 맞게 변경하여 학습합니다.
따라서, 새로운 데이터셋에서는 이미지의 카테고리를 결정하는 부분인 마지막 완전 연결층만 학습하고, 나머지 합성곱층 계층들은 사전 훈련된 가중치를 그대로 사용하여 학습되지 않도록 고정합니다.
여기에서 사용 가능한 이미지 분류 모델은 다음과 같습니다.
- VGG16
- VGG19
- ResNet50
- InceptionV3
- Xception
- MobileNet

1. 라이브러리 호출
import os
import time
import copy
import glob
import cv2 # 앞에서 설치했던 OpenCV
import shutil
import torch
import torchvision # 컴퓨터 비전 용도의 패키지
import torchvision.tranforms as transforms # 데이터 전처리를 위해 사용되는 패키지
import torchvision.models as models # 다양한 파이토치 네트워크를 사용할 수 있도록 도와주는 패키지
import torch.nn as nn
import optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt2. 이미지 데이터 전처리 방법 정의
data_path = './data/catanddog/train'
transform = transforms.Compose( ## 1
[
transforms.Resize([256,256]),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder( ## 2
data_path,
transform = transform
)
train_loader = torch.utils.data.DataLoader( ## 3
train_dataset,
batch_size = 32,
num_workers = 8,
shuffle = True
)
print(len(train_dataset))1. torchvision.transform은 이미지 데이터를 변환하여 모델(네트워크)의 입력으로 사용할 수 있게 변환해 줍니다.
- transforms.Resize([256, 256]): 이미지를 크기를 조정, 즉 256X256 크기로 이미지 데이터를 조정합니다.
- transforms.RandomResizedCrop(224): 이미지 중 임의의 영역을 자르고, 크기를 (224,224)로 조절합니다.
- transforms.RandomHorizontalFlip(): 이미지를 수평 방향으로 랜덤하게 뒤집습니다.
- transforms.ToTensor(): 이미지 데이터를 텐서로 변환합니다.
2. datasets.ImageFolder는 데이터로더가 데이터를 불러올 대상(혹은 경로)과 방법(전처리)을 정의하며, 사용하는 파라미터는 다음과 같습니다.
< torchvision.datasets.ImageFolder(data_path, transform = transform) 파라미터 >
- data_path: 불러올 데이터가 위치한 경로
- transform: 이미지 데이터에 대한 전처리
torchvision.datasets.ImageFolder() 함수는 지정된 폴더 내부의 이미지 파일들을 읽어 들여서 데이터셋을 생성합니다. 이 함수는 이미지가 저장된 폴더의 경로를 입력으로 받아서, 해당 폴더 내부의 이미지를 클래스별로 분류합니다. 예를 들어, 폴더 내부에 cat 폴더와 dog 폴더가 있다면, cat 폴더에 있는 모든 이미지는 cat 클래스에 속하고, dog 폴더에 있는 모든 이미지는 dog 클래스에 속하는 것입니다.
3. torch.utils.data.DataLoader() 함수를 이용하여 데이터셋을 미니배치 단위로 로딩하는(불러오는) 코드입니다.
DataLoader() 함수는 데이터셋을 미니배치 단위로 나누어서 학습에 이용할 수 있도록 도와줍니다.
< train_loader=torch.utils.data.DataLoader(train_dataset, batch_size=32, num_workers = 8, shuffle = True) 파라미터>
- 첫 번째 파라미터: 데이터셋을 지정
- batch_size: 한 번에 불러올 데이터양을 결정하는 배치 크기 설정
- num_workers: 데이터를 불러올 때 하위 프로세스를 몇 개 사용할지 설정
- shuffle: 데이터를 무작위로 섞을지 지정
3. 학습에 사용될 이미지 출력
import matplotlib.pyplot as plt
import numpy as np
# train_loader 에서 첫 번째 배치를 가져와 이미지와 라벨을 sample, labels에 저장
samples, labels = next(iter(train_loader)) ## 1
# 각 클래스의 이름을 숫자와 매칭하여 저장 (총 2개)
classes = {0:'cat',1:'dog'}
fig, axs = plt.subplots(nrows=4, ncols=6, figsize=(16, 10)) # 4행 6열의 서브플롯을 생성
for ax, image, label in zip(axs.flatten(), samples, labels):
image = np.transpose(image.numpy(), (1, 2, 0)) # 차원 변환: (C, H, W) -> (H, W, C)
ax.imshow(image, cmap='gray') # 흑백 이미지로 출력
ax.set_title(classes[label.item()], fontsize=12) # label.item(): torch.Tensor 타입의 스칼라 값(정수)을 얻기 위해 사용
ax.set_xticks([])
ax.set_yticks([])
plt.tight_layout()
plt.show()
1. samples, labels = next(iter(train_loader))는 DataLoader에서 batch_size만큼 데이터를 로드한 후, 그중 첫 번째 batch를 가져오는 코드입니다. iter(train_loader)는 train_loader의 iterator를 반환하고, next 함수를 이용해 그중 첫 번째 batch를 가져오고 있습니다. 간단히 정리하면 train_loader에서 데이터를 하나씩 꺼내 오겠다는 의미입니다.
4. 사전 훈련된 모델 내려받기
resnet18 = models.resnet18(pretrained=True) # pretrained=True: 사전 학습된 가중치를 사용하겠다.
5. 사전 훈련된 모델의 파라미터 학습 유무 지정
def set_parameter_requires_grad(model, feature_extracting = True):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False ## 1
set_parameter_requires_grad(resnet18)1. requires_grad는 해당 파라미터에 대한 미분 값을 계산할지 여부를 결정하는데, 이를 False로 설정하면 해당 파라미터에 대한 학습이 불가능해집니다. 따라서 모델의 일부(합성곱층, 풀링층)를 고정하고 추가로 추가한 fully connected layer 등 일부 파라미터만 학습하고자 할 때, 해당 파라미터의 requires_grad를 False로 설정합니다. 이렇게 함으로써 fine-tuning을 위해 feature extraction과 fine-tuning 단계를 분리하고, 학습이 필요한 파라미터만 업데이트할 수 있습니다.
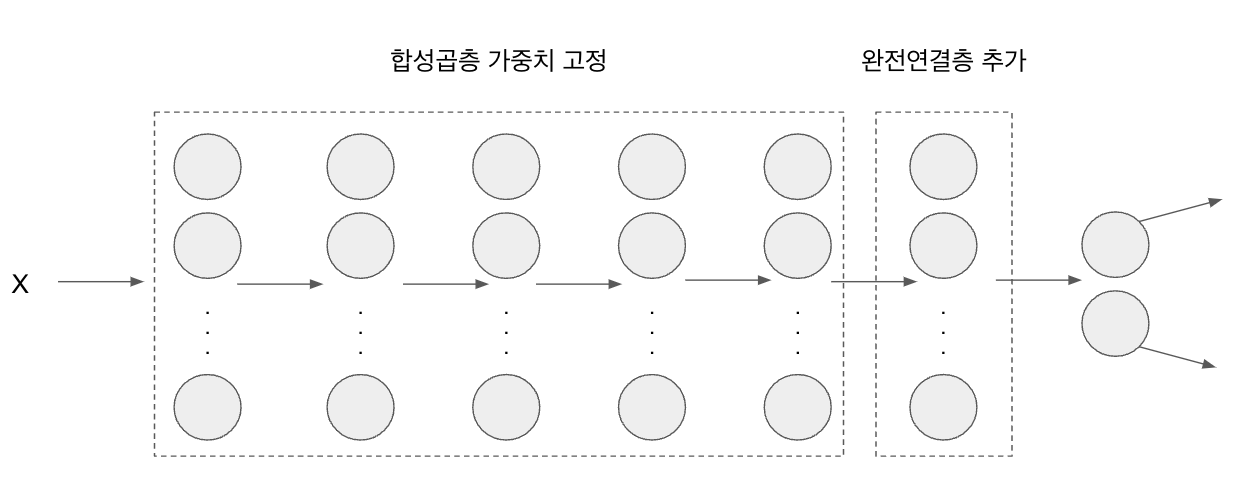
내려받은 ResNet18의 마지막 부분에 완전연결층을 추가합니다. 추가된 완전연결층은 개와 고양이 클래스를 분류하는 용도로 사용됩니다.
6. ResNet18에 완전연결층 추가
resnet18.fc = nn.Linear(512,2) # 2는 클래스가 두 개라는 의미7. 모델의 파라미터 값 확인
# model.named_parameters()는 모델에 접근하여 파라미터 값들을 가져올 때 사용
for name, param in resnet18.named_parameters():
if param.requires_grad:
print(name, param.data)- fc.weight tensor([[-0.0215, 0.0117, 0.0099, ..., 0.0025, -0.0111, -0.0093], [ 0.0228, -0.0032, -0.0102, ..., 0.0163, -0.0384, 0.0266]])
- fc.bias tensor([0.0014, 0.0305])
8. 모델 객체 생성 및 손실 함수 정의
model = models.resnet18(pretrained=True) # 모델의 객체 생성
for param in model.parameters(): # 모델의 합성곱층 가중치 고정
param.requres_grad = False
model.fc = torch.nn.Linear(512,2)
for param in model.fc.parameters(): # 완전연결층은 학습
param.requires_grad = True
optimizer = torch.optim.Adam(model.fc.parameters())
cost = torch.nn.CrossEntropyLoss() # 손실 함수 정의
print(model)9. 모델 학습을 위한 함수 생성
데이터 준비, 네트워크 생서잉 완료되었으므로 이제 모델을 학습시켜야 합니다. 모델 학습을 위한 함수를 생성합니다.
def train_model(model, dataloaders, criterion, optimizer, device, num_epochs=13, is_train=True):
since = time.time() # 현재 시간
acc_history = []
loss_history = []
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
running_loss = 0.0 # 배치마다 손실 누적
running_corrects = 0 # 배치마다 정확도 누적
for inputs, labels in dataloaders:
inputs, labels = inputs.to(device), labels.to(device)
model.to(device)
outputs = model(inputs) # 데이터(batch)를 모델에 입력하여 출력값 계산
loss = criterion(outputs, labels) # 손실값 계산
optimizer.zero_grad() # 이전에 계산된 그래디언트 값 초기화
loss.backward() # 손실에 대한 그래디언트 계산
optimizer.step() # 계산된 그래디언트를 이용하여 가중치 업데이트
with torch.no_grad(): ## 1 # 평가중에는 그래디언트가 불필요하기 때문에, 그래디언트 계산 비활성화
preds = torch.argmax(outputs, 1) # 각 행의 최댓값의 인덱스 값 추출
running_loss += loss.item() * inputs.size(0) ## 2 # 현재 배치에서 계산된 손실값
running_corrects += torch.sum(preds == labels) # 현재 배치에서 예측값과 정답(label)이 일치한 개수
epoch_loss = running_loss / len(dataloaders.dataset) ## 3 # 전체 데이터셋에 대한 손실 평균
epoch_acc = running_corrects.double() / len(dataloaders.dataset) ## 4 # 전체 데이터셋에 대한 정확도 평균
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
acc_history.append(epoch_acc.item()) # 각 epoch에서의 정확도 값 저장
loss_history.append(epoch_loss) # 각 epoch에서의 손실값 저장
torch.save(model.state_dict(), os.path.join('./data/catanddog/', '{0:0=2d}.pth'.format(epoch))) ## 5 # 모델 재사용을 위해 저장
print()
time_elapsed = time.time() - since # 학습이 끝난 시간 - 학습 시작 시간 = 학습 총 소요 시간
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) # 분/초로 변환하여 출력
print('Best Acc: {:4f}'.format(best_acc))
return acc_history, loss_history # 모델의 정확도, 모델의 오차.item() : torch.Tensor 타입의 스칼라 값(정수)을 얻기 위해 사용
1. with torch.no_grad()
PyTorch에서 제공하는 기능 중 하나로, 해당 블록 내에서는 autograd engine이 계산한 변수들의 추적을 멈춥니다.
주로 모델의 평가(inference) 단계에서 사용됩니다.
평가 단계에서는 역전파를 수행하지 않기 때문에, autograd engine이 추적한 계산 그래프를 구성할 필요가 없습니다.
따라서 with torch.no_grad(): 블록 내에서 수행되는 계산은 모두 연산 그래프로 기록되지 않아 메모리 사용량을 줄이고, 계산 속도를 높일 수 있습니다.
2. running_loss += loss.item() * inputs.size(0)
배치 단위로 손실값을 계산하고, 이때 배치의 원소 개수인 input.size(0)를 곱하여 현재 배치에서 계산된 손실값을 구합니다.
즉, 현재 배치의 모든 데이터에 대한 손실값을 구하려면 해당 배치의 손실값에 데이터의 개수를 곱하면 됩니다.
이렇게 구해진 현재 배치에서의 손실값은 전체 데이터셋에서의 손실값을 구하는 데 사용됩니다.
3. epoch_loss = running_loss / len(dataloaders.dataset)
len(dataloaders)는 dataloader의 개수를 반환하는 것이 아니라, dataloader의 크기(배치의 개수)를 반환합니다. len(dataloaders.dataset)은 dataloader에 사용되는 전체 데이터셋의 크기를 반환합니다.
따라서 이 값을 사용하여 각 epoch의 손실값과 정확도를 계산하는 것이 올바른 방법입니다.
4. running_corrects.double() / len(dataloaders.dataset)
running_corrects.double()는 running_corrects 값을 double형으로 바꾼 것입니다. 이 작업은 PyTorch의 기본 데이터 타입인 float32 대신 float64를 사용하기 위한 것입니다. 이것은 학습 도중에 데이터 타입에 따라 손실값이나 모델의 성능이 달라지는 경우를 방지하기 위한 것입니다.
5. torch.save(model.state_dict(), os.path.join('./data/catanddog/', '{0:0=2d}.pth'.format(epoch)))
torch.save 함수는 파이토치 모델의 상태를 저장하기 위한 함수입니다.
- 첫 번째 인자: 모델의 상태를 나타내는 state_dict 모델의 각 레이어별 가중치와 편향 등의 매개변수를 저장하는 파이썬 사전(Dictionary) 객체입니다. 이는 학습된 모델의 매개변수를 담고 있습니다.
- 두 번째 인자: 모델 파라미터를 저장할 경로와 파일 이름입니다. 위 코드에서는 ./data/catanddog/ 폴더에 {0:0=2d}.pth 파일 이름으로 현재 학습된 모델 파라미터를 저장합니다. 이렇게 모델 파라미터를 저장해 두면, 나중에 모델을 불러와서 추가 학습을 진행하거나, 다른 데이터셋에서 전이학습을 할 때 사용할 수 있습니다.
({0:0=2d}는 0으로 채워진 두 자리 숫자의 형태로, 현재 epoch 수를 표시하는 역할을 합니다. 따라서, 00.pth, 01.pth, 02.pth, ... 와 같이 파일이 저장됩니다.)
10. 파라미터 학습 결과를 옵티마이저에 전달(weight, bias 전달)
그리고 마지막으로 ResNet18에 추가된 완전연결층은 학습을 하도록 설정합니다.
학습을 통해 얻어지는 파라미터를 옵티마이저에 전달해서 최종적으로 모델 학습에 사용합니다.
params_to_update = []
for name,param in resnet18.named_parameters():
if param.requires_grad == True:
params_to_update.append(param) # 파라미터 학습 결과를 저장
print("\t",name)
optimizer = optim.Adam(params_to_update) # 학습 결과를 옵티마이저에 전달ResNet18 모델의 모든 파라미터 중 requires_grad가 True인 파라미터만 optimizer에 등록하는 코드입니다.
resnet18.named_parameters()는 ResNet18 모델의 모든 파라미터를 (이름, 파라미터) 쌍의 형태로 반환합니다.
이때 파라미터의 requires_grad 속성이 True인 파라미터만 optimizer에 등록하게 됩니다.
params_to_update 리스트에 등록되는 파라미터들은 실제로 학습에 사용될 파라미터들입니다. 다른 파라미터들은 학습 도중 업데이트 되지 않으므로 메모리를 아낄 수 있습니다.
11. 모델 학습
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
criterion = nn.CrossEntropyLoss()
train_acc_hist, train_loss_hist = train_model(resnet18, train_loader, criterion, optimizer, device)GPU가 사용 가능한 경우 "cuda"를 사용하고, 그렇지 않은 경우에는 "cpu"를 사용하여 device 변수에 할당합니다.
그리고 CrossEntropyLoss() 함수를 이용하여 손실함수를 정의하고, train_model() 함수를 이용하여 학습을 수행합니다.
train_model() 함수의 인자로는 (모델, 학습 데이터, 손실 함수, 옵티마이저, 장치(CPU or GPU))입니다.
모델 학습에 대한 결과입니다.

약 93%로 상당히 높은 정확도를 보여주고 있습니다. train 데이터로는 학습이 잘되었다고 할 수 있습니다.
이제 test 데이터를 이용하여 모델 정확도를 확인해 봅시다.
12. test 데이터 호출 및 전처리
test 데이터를 불러와 전처리를 합니다.
test_path = './data/catanddog/test'
transform = transforms.Compose(
[
transforms.Resize(224), # 이미지 크기를 224 X 224로 변경
transforms.CenterCrop(224), # 이미지 중심 부분을 224 X 224 로 자름
transforms.ToTensor(), # 이미지를 텐서 형식으로 변환
])
test_dataset = torchvision.datasets.ImageFolder( # 전처리 단계가 적용된 test 데이터셋 생성
root=test_path,
transform=transform
)
test_loader = torch.utils.data.DataLoader( # test 데이터를 배치 단위로 처리
test_dataset,
batch_size=32,
num_workers=1,
shuffle=True
)
print(len(test_dataset))13. test 데이터 평가 함수 생성
test 데이터가 준비되었습니다.
test 데이터 평가를 위한 함수를 생성합니다.
def eval_model(model, dataloaders, device):
since = time.time() # 현재 시간
acc_history = []
best_acc = 0.0
saved_models = glob.glob('./data/catanddog/' + '*.pth') ## 1
saved_models.sort()
print('saved_model', saved_models)
for model_path in saved_models: # 검색된 각 모델 파일에 대해 다음을 수행
print('Loading model', model_path)
model.load_state_dict(torch.load(model_path)) # 모델의 가중치 로드
model.eval() # 모델을 평가모드로 설정. 이는 학습 중에는 사용되지만 평가중에는 사용되지 않는 기능들을 비활성화
model.to(device)
running_corrects = 0
for inputs, labels in dataloaders: # 각 배치에 대해 다음을 수행
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad(): # 평가중에는 그래디언트가 불필요하기 때문에, 그래디언트 계산 비활성화
outputs = model(inputs)
preds = torch.argmax(outputs.data, 1)
running_corrects += torch.sum(preds == labels.data)
epoch_acc = running_corrects.double() / len(dataloaders.dataset)
print('Acc: {:.4f}'.format(epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
acc_history.append(epoch_acc.item())
print()
time_elapsed = time.time() - since
print('Validation complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best Acc: {:4f}'.format(best_acc))
return acc_historyeval_model 함수는 저장된 모델들을 로드하여 각각에 대한 성능을 평가합니다.
평가는 주어진 데이터 로더에 있는 데이터셋을 사용하여 수행되며, 각 모델의 정확도가 계산되어 최고 정확도를 가진 모델을 찾습니다.
1. saved_models = glob.glob('./data/catanddog/' + '*.pth')
glob는 현재 디렉토리에서 원하는 파일들만 추출하여 가져올 때 사용합니다. 즉 './data/catanddog/' 디렉토리에서 .pth 확장자를 갖는 파일을 검색한다는 의미입니다. (.pth라는 확장자를 갖는 파일은 훈련 데이터로 모델을 훈련시킬 때 생성된 파일입니다.)
14. test 데이터를 평가 함수에 적용
이제 모델 평가 함수에 test 데이터를 적용해서 실제로 성능(정확도)을 측정합니다.
val_acc_hist = eval_model(resnet18, test_loader, device)해당 코드는 미리 학습된 ResNet18 모델을 이용하여 test dataset을 평가하는 과정을 거칩니다.
eval_model() 함수를 이용하여 ResNet18 모델의 정확도를 계산하고, val_acc_hist 변수에 결과를 저장합니다.
test 데이터의 정확도를 출력한 결과입니다.

test 데이터 역시 94% 정도의 높은 정확도를 보입니다.
15. train & test 정확도를 그래프로 확인
plt.plot(train_acc_hist)
plt.plot(val_acc_hist)
plt.show()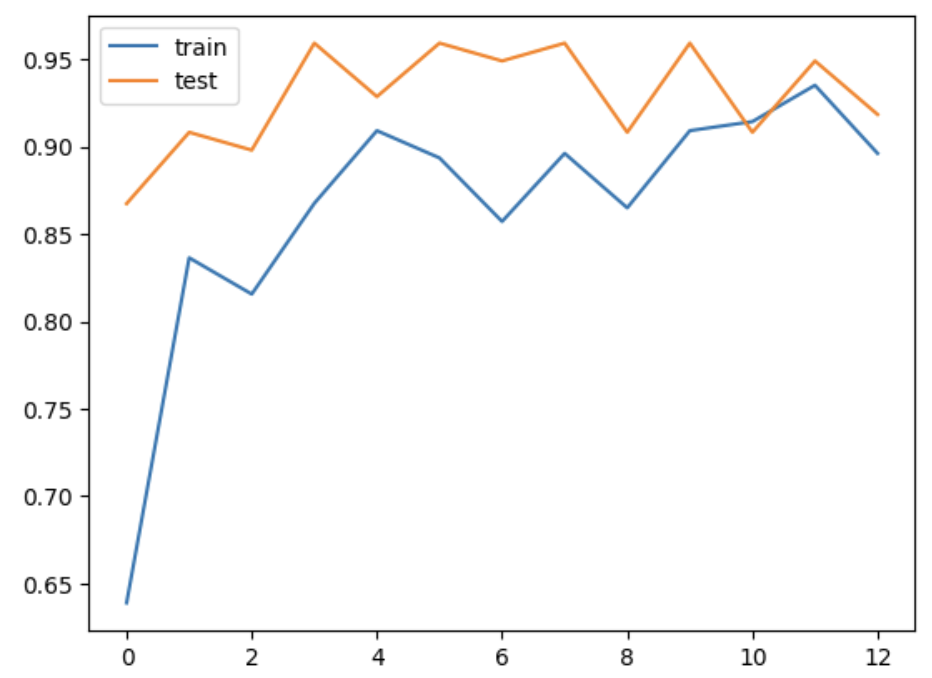
train과 test 데이터에 대해 epoch가 진행될 때마다 정확도를 출력한 결과입니다.
train와 test 데이터 모두 epoch가 진행될수록 정확도가 높아지고 있습니다.
16. train 데이터의 오차에 대한 그래프 확인
plt.plot(train_loss_hist)
plt.show()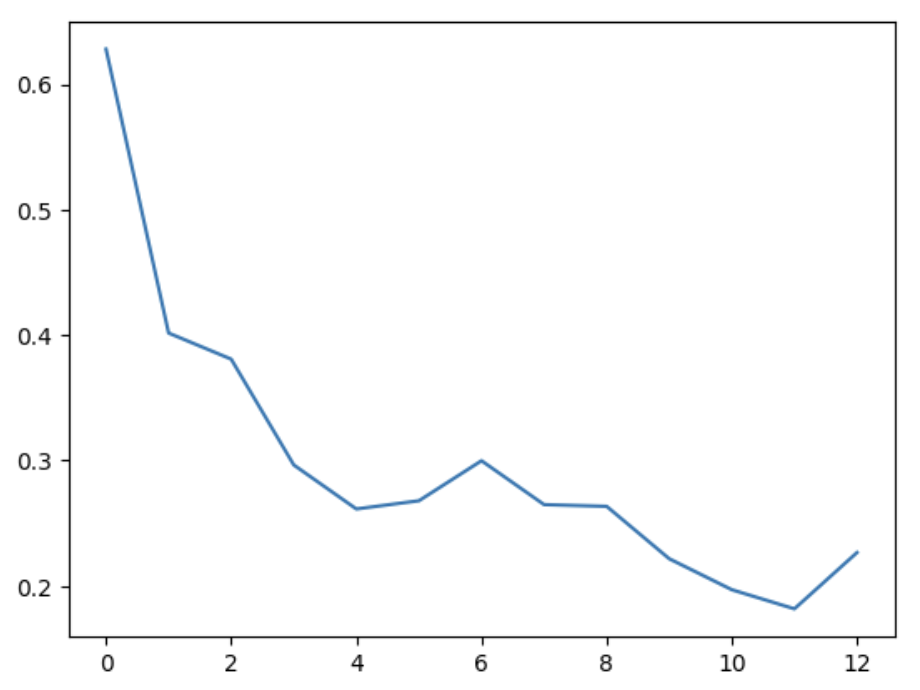
epoch가 진행될수록 오차가 낮아지고 있기 때문에 학습이 잘 되었다고 할 수 있습니다.
미세 조정 기법
미세 조정(fine-tuning) 기법은 특성 추출 기법을 확장한 방법으로, 사전 훈련된 모델을 가져와서 추가로 합성곱층(convolutional layers)과 데이터 분류기(classifier)의 가중치를 업데이트하여 모델을 훈련시키는 방식입니다.
특성 추출 기법은 이미 잘 추출된 특성을 사용하여 성능을 높일 수 있습니다. 그러나 특성이 잘못 추출되었다면 (예를 들어, ImageNet 데이터셋의 이미지 특징과 전자상거래 물품의 이미지 특징이 다른 경우) 미세 조정 기법을 통해 새로운 (전자상거래) 이미지 데이터를 사용하여 네트워크의 가중치를 업데이트하여 특성을 다시 추출할 수 있습니다. 즉, 사전 학습된 모델을 목적에 맞게 재학습시키거나 일부 가중치를 재학습시키는 것입니다.
미세 조정 기법은 분석하려는 데이터셋에 잘 맞도록 사전 훈련된 네트워크의 파라미터를 조정하는 기법입니다. 이 기법은 데이터셋의 크기와 사전 훈련된 모델 간의 유사성에 따라 전략을 설정할 수 있습니다.
- 데이터셋이 크고 사전 훈련된 모델과 유사성이 낮은 경우: 전체 모델을 재학습시킵니다. 큰 데이터셋을 활용하므로 전체 모델을 학습시키는 것이 좋은 전략입니다.
- 데이터셋이 크고 사전 훈련된 모델과 유사성이 높은 경우: 합성곱층의 뒷부분과 데이터 분류기만 학습시킵니다. 데이터셋이 유사하기 때문에 강력한 특징을 가진 합성곱층의 뒷부분과 데이터 분류기를 새로 학습하면 최적의 성능을 얻을 수 있습니다.
- 데이터셋이 작고 사전 훈련된 모델과 유사성이 작은 경우: 합성곱층의 일부분과 데이터 분류기를 학습시킵니다. 데이터가 적기 때문에 일부 계층에 미세 조정 기법을 적용한다고 해도 효과가 없을 수 있습니다. 따라서 합성곱층 중 어디까지 새로 학습시켜야 할지 적당히 설정해주어야 합니다.
- 데이터셋이 작고 사전 훈련된 모델과 유사성이 높은 경우 : 데이터 분류기만 학습시킵니다. 데이터가 적기 때문에 많은 계층에 미세 조정 기법을 적용하면 과적합이 발생할 수 있습니다. 따라서 최종 데이터 분류기인 완전연결층에 대해서만 미세 조정 기법을 적용합니다.
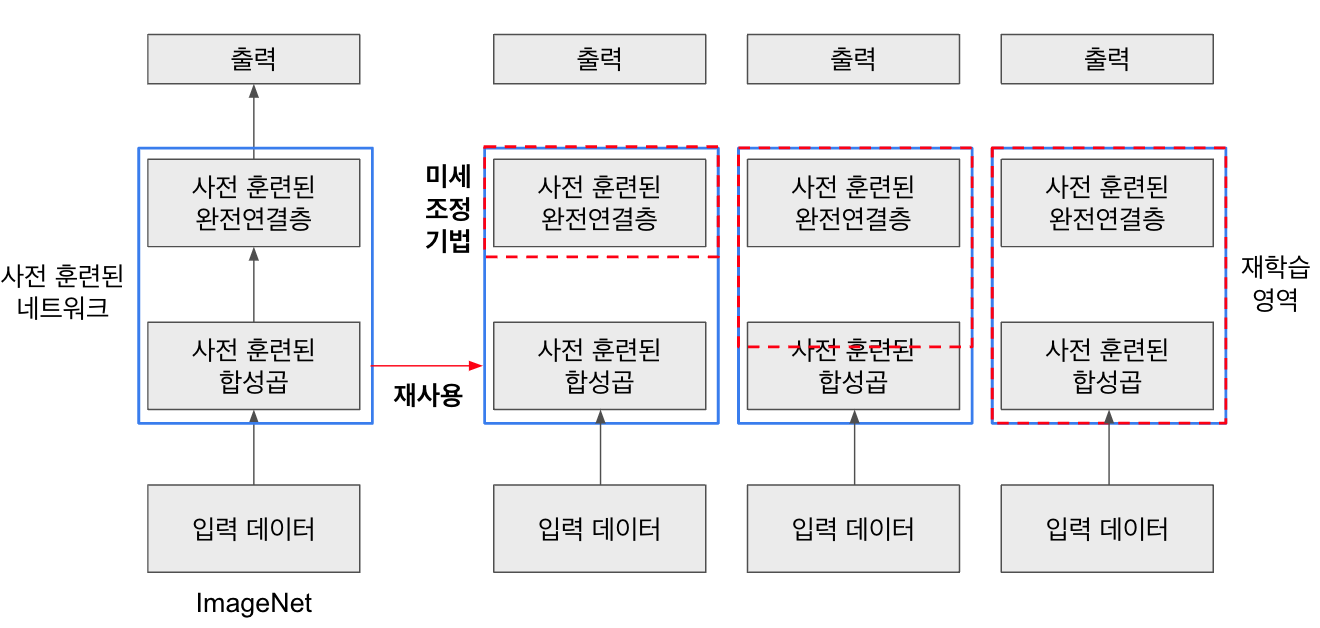
미세조정기법은 파라미터 업데이트 과정에서 파라미터에 큰 변화를 주게 되면 과적합 문제가 발생할 수 있기 때문에 정교하고 미세한 파라미터 업데이트가 필요합니다.
'pytorch' 카테고리의 다른 글
| [pytorch] 이미지 분류를 위한 AlexNet 구현 (6) | 2023.05.31 |
|---|---|
| [pytorch] 이미지 분류를 위한 LeNet-5 구현 (0) | 2023.05.15 |
| [pytorch] Convolutional Neural Network (CNN) 로 FashionMNIST 구현해보기 (0) | 2023.04.28 |
| [pytorch] Deep Neural Network (DNN) 로 FashionMNIST 구현해보기 (0) | 2023.04.25 |
| [pytorch] 합성곱층 - Filter(stride / padding) (0) | 2023.04.09 |