AlexNet은 컴퓨터 비전 분야의 발전에 중요한 역할을 한 합성곱 신경망(CNN) 아키텍처입니다.
이는 Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton에 의해 개발되었으며, 2012년 ImageNet 대규모 시각 인식 챌린지(ILSVRC)에서 우승하였습니다. 이 대회는 딥러닝의 전환점을 표시하며, CNN이 이미지 분류 작업에서 강력한 성능을 보여준 것을 보여주었습니다.
AlexNet 아키텍처는 총 여덟 개의 레이어로 구성되어 있으며, 다섯 개의 합성곱 레이어와 세 개의 완전 연결 레이어로 이루어져 있습니다.
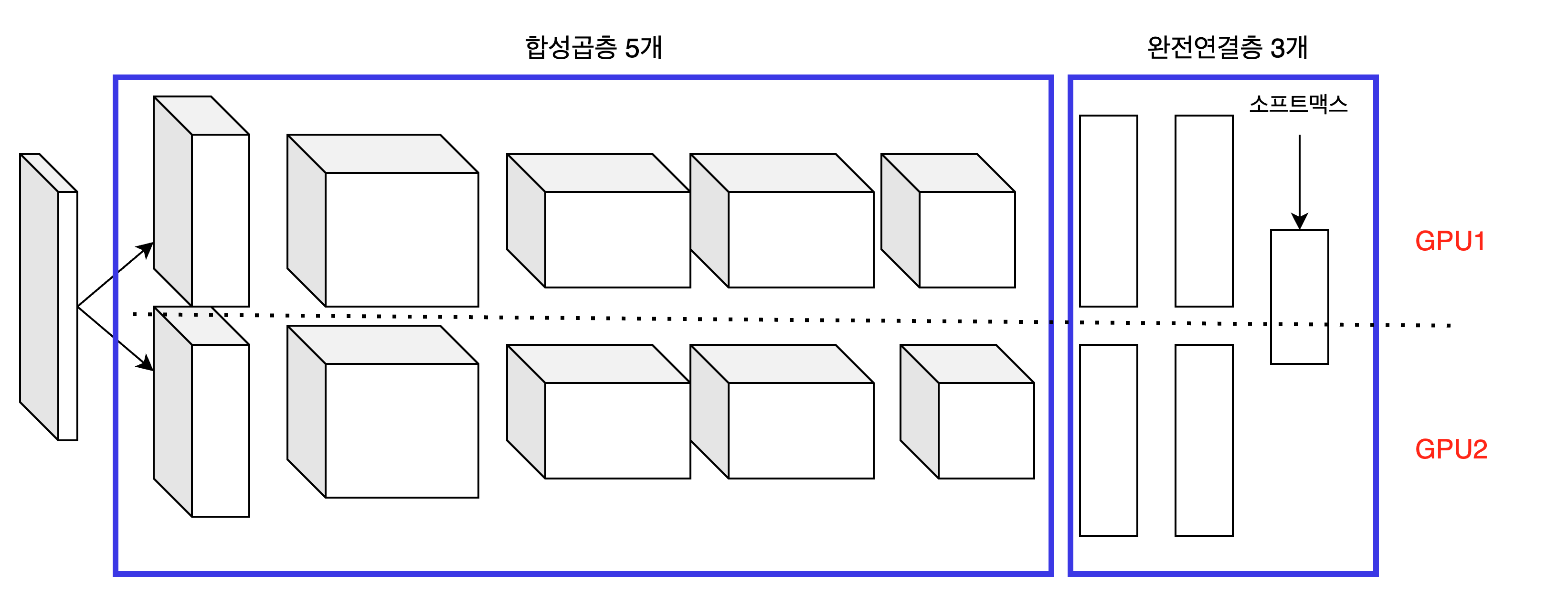
- 입력 레이어: 입력 이미지를 받습니다. 일반적으로 픽셀 값의 행렬 형태로 제공됩니다.
- 합성곱 레이어 1: 첫 번째 합성곱 레이어는 입력 이미지에 학습된 필터를 적용하여 엣지, 코너, 질감과 같은 특징을 추출합니다.
- ReLU 활성화: ReLU 활성화 함수를 원소별로 적용하여 비선형성을 도입하며, 더 복잡한 패턴을 학습하는 데 도움을 줍니다.
- 최대 풀링: 첫 번째 최대 풀링 레이어는 피처 맵을 다운샘플링하여 공간 차원을 줄이고 가장 중요한 특징을 추출합니다.
- 합성곱 레이어 2와 3: 이러한 레이어는 이전 레이어의 피처 맵에 추가적인 합성곱 필터를 적용하여 고수준의 특징을 추출합니다.
- ReLU 활성화: 첫 번째 ReLU 활성화와 유사하게 비선형성을 도입합니다.
- 최대 풀링: 다른 최대 풀링 레이어는 피처 맵의 공간 차원을 더욱 줄입니다.
- 합성곱 레이어 4와 5: 이러한 레이어는 이전 레이어에서 더욱 추상적인 특징을 추출합니다.
- ReLU 활성화: 다섯 번째 합성곱 레이어의 출력에 ReLU 활성화를 적용합니다.
- 최대 풀링: 마지막 최대 풀링 레이어는 피처 맵을 최종적으로 다운샘플링합니다.
- 플래튼: 피처 맵은 일차원 벡터로 펼쳐져 완전 연결 레이어에 입력됩니다.
- 완전 연결 레이어 1, 2, 3: 이러한 레이어는 학습된 특징을 기반으로 분류를 수행합니다. 마지막 완전 연결 레이어는 최종 출력 logits을 생성합니다.
- 소프트맥스 활성화: 소프트맥스 함수를 logits에 적용하여 각 클래스의 확률로 변환합니다.
| 계층 유형 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
| 이미지 | 1 | 227X227 | - | - | - |
| 합성곱층 | 96 | 55X55 | 11X11 | 4 | 렐루(Relu) |
| 최대 풀링층 | 96 | 27X27 | 3X3 | 2 | - |
| 합성곱층 | 256 | 27X27 | 5X5 | 1 | 렐루(Relu) |
| 최대 풀링층 | 256 | 13X13 | 3X3 | 2 | - |
| 합성곱층 | 384 | 13X13 | 3X3 | 1 | 렐루(Relu) |
| 합성곱층 | 384 | 13X13 | 3X3 | 1 | 렐루(Relu) |
| 합성곱층 | 384 | 13X13 | 3X3 | 1 | 렐루(Relu) |
| 최대 풀링층 | 256 | 6X6 | 3X3 | 2 | 렐루(Relu) |
| 완전연결층 | 256 | 4096 | - | - | |
| 완전연결층 | - | 4096 | - | - | 렐루(Relu) |
| 완전연결층 | - | 1000 | - | - | 소프트맥스(softmax) |
GPU-1 에서는 주로 컬러와 상관없는 정보를 추출하기 위한 커널이 학습되고,
CPU-2에서는 주로 컬러와 관련된 정보를 추출하기 위한 커널이 학습됩니다.
1. 라이브러리 호출
import torch
import torchvision
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms # 이미지 변환(전처리) 기능을 제공
from torch.autograd import Variable
from torch import optim # 경사하강법을 이용하여 가중치를 구하기 위한 옵티마이저
import os # 파일 경로에 대한 함수들을 제공
import cv2
from PIL import Image
from tqdm import tqdm_notebook as tqdm # 진행 상황 표현
import random
import torch.nn as nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")tqdm은 진행 상태를 시각적으로 보여주기 위해 바(bar) 형태로 표시하는 라이브러리입니다.
주로 모델 훈련 과정에서 진행 상태를 확인하고자 할 때 사용됩니다.
tqdm은 반복문이나 작업의 진행 상황을 모니터링하며, 진행 막대와 텍스트로 표시하여 사용자에게 진행 상태를 시각적으로 전달합니다.
이를 통해 모델의 학습 진행 상황을 실시간으로 확인하고, 훈련 시간 등의 정보를 제공하여 개발자가 효율적으로 모델을 관리할 수 있게 도와줍니다.
2. 이미지 데이터셋 전처리
먼저 모델 학습에 필요한 데이터셋의 전처리(텐서 변환)가 필요합니다.
class ImageTransform():
def __init__(self, resize, mean, std):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]), ## 1
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
def __call__(self, img, phase): ## 2
return self.data_transform[phase](img)1. torchvision.transform은 이미지 데이터를 변환하여 모델(네트워크)의 입력으로 사용할 수 있게 변환해 줍니다.
- transforms.Compose : 이미지를 변형할 수 있는 방식들의 묶음입니다.
- transforms.RandomResizedCrop(resize, scale=(0.5,1.0)): 이미지 중에서 임의의 영역을 자르고(resize), 크기를 조절하는 함수입니다. 먼저, 입력된 이미지의 높이와 너비 중 작은 쪽을 resize(224x224)로 지정된 크기로 조정합니다. 그리고 scale 인자로 지정된 범위 내에서 임의의 비율을 선택하여 이미지를 늘리거나(resize) 줄입니다. 이때, scale은 자를 이미지의 비율을 의미하며, (0.5, 1.0)과 같이 지정되면 원래 이미지 크기의 50%에서 100% 크기까지 임의로 자르게 됩니다. 즉, 이 함수는 입력된 이미지에서 임의의 부분을 자르고, 크기를 조정하여 데이터 증강(augmentation)을 수행하는 데 사용됩니다.
- transforms.RandomHorizontalFlip(): 입력된 이미지를 50%의 확률로 좌우 반전시키는(preprocessing) 함수입니다.
즉, 훈련 이미지 중 반은 위아래 뒤집힌 상태로 두고, 반은 그대로 사용합니다. - transforms.ToTensor() : torchvision 라이브러리의 메서드 중 ImageFolder를 비롯하여, 이미지를 읽을 때 PIL(Python Imaging Library)을 사용합니다. PIL을 사용하여 이미지를 읽으면 생성되는 이미지는 배열의 차원이 (높이 H x 너비 W x 채널 수 C)로 표현되고, 각 픽셀의 값은 0~255 범위를 가집니다.
PyTorch의 모델은 입력 데이터의 형태가 (배치 크기 x 채널 수 C x 높이 H x 너비 W)로 정규화된 float32 형태여야 합니다. 따라서 PIL 이미지나 NumPy 배열(ndarray)을 PyTorch 텐서로 변환할 때는 transforms.ToTensor() 메서드를 사용합니다. 이 메서드는 입력된 이미지나 배열의 데이터 타입을 float32로 변경하고, 이미지의 픽셀 값을 0~1 범위로 정규화하여 PyTorch 텐서로 반환합니다. 변환된 텐서는 모델의 입력 데이터로 사용됩니다. 예를 들어, 입력 이미지가 크기가 (H, W, C)인 ndarray일 경우에는 ToTensor 함수를 사용하여 크기가 (C, H, W)인 PyTorch 텐서로 변환됩니다. - transforms.Normailze(mean, std) : 전이 학습에서 사용되는 사전 훈련된 모델들은 대부분 ImageNet 데이터셋에서 훈련되었습니다. 따라서 사전 훈련된 모델을 사용하기 위해서는 ImageNet 데이터의 각 채널별 평균과 표준편차에 맞는 정규화를 해주어야 합니다.
즉, Normalize 메서드 안에 사용된 (mean:0. 485, 0. 456, 0. 406), (std:0.229.0.224.0. 225)는 ImageNet에서 이미지들의 RGB 채널마다 평균과 표준편차를 의미합니다. 참고로 OpenCV를 사용해서 이미지를 읽어 온다면 RGB가 아닌 BGR 이미지이므로 채널 순서에 주의해야 합니다.
2. __call__ 메서드는 해당 클래스의 인스턴스를 호출할 때 실행되는 메서드입니다. 위 코드에서 ImageTransform 클래스의 인스턴스를 호출하면 __call__ 메서드가 실행되고, 이 메서드는 전달된 이미지와 처리할 단계(phase)에 따라서 data_transform 딕셔너리에서 해당하는 전처리 과정을 선택하여 적용합니다.
즉, __call__ 메서드는 입력 이미지와 전처리 단계를 받아서 해당 단계에 맞는 전처리 과정을 수행하고, 결과 이미지를 반환하는 역할을 합니다.
- img는 처리할 이미지입니다. 전처리 과정은 이 이미지에 대해서 수행됩니다.
- phase는 현재 전처리 단계를 나타내는 문자열입니다. 위 코드에서는 'train' 또는 'val' 중 하나가 사용됩니다. 이 값에 따라서 data_transform 딕셔너리에서 적용할 전처리 과정이 결정됩니다. 'train'인 경우에는 RandomResizedCrop과 RandomHorizontalFlip이 적용되고, 'val'인 경우에는 Resize와 CenterCrop이 적용됩니다.
즉, __call__ 메서드는 입력 이미지 img와 전처리 단계 phase를 받아서 해당 단계에 맞는 전처리 과정을 수행하고, 결과 이미지를 반환하는 역할을 합니다.
3. 이미지 데이터셋을 불러온 후 훈련, 검증, 테스트로 분리
우리가 사용하는 노트북은 성능이 좋지 않다고 가정한 채 진행했기 때문에 train 데이터셋을 400개로 제한했습니다.
AlexNet은 파라미터는 6000만 개 사용하는 모델입니다. 이때 충분한 데이터가 없으면 과적합이 발생하는 등 test 데이터에 대한 성능이 좋지 않습니다. 성능이 좋은 결과를 원한다면 충분한 데이터셋을 확보하고 테스트를 진행하면 됩니다.
cat_directory = './dogs-vs-cats/Cat/'
dog_directory = './dogs-vs-cats/Dog/'
## 1
cat_images_filepaths = sorted([os.path.join(cat_directory, f)
for f in os.listdir(cat_directory)])
dog_images_filepaths = sorted([os.path.join(dog_directory, f)
for f in os.listdir(dog_directory)])
## 2
images_filepaths = [*cat_images_filepaths, *dog_images_filepaths]
## 3
correct_images_filepaths = [i for i in images_filepaths if cv2.imread(i) is not None]
random.seed(42) ## 4
random.shuffle(correct_images_filepaths)
# 일부 데이터만 사용
train_images_filepaths = correct_images_filepaths[:400]
val_images_filepaths = correct_images_filepaths[400:-10]
test_images_filepaths = correct_images_filepaths[-10:]
print(len(train_images_filepaths), len(val_images_filepaths), len(test_images_filepaths))1. cat_images_filepaths = sorted([os.path.join(cat_directory, f) for f in os.listdir(cat_directory)])
- os.listdir(cat_directory): 주어진 경로(cat_directory)에 있는 모든 파일과 디렉토리의 이름을 리스트 형태로 반환하는 함수입니다. 위 코드에서 cat_directory는 고양이 이미지가 저장된 디렉토리의 경로를 의미합니다.
- os.path.join: 주어진 경로들을 하나의 경로로 연결해 주는 함수입니다.
예를 들어, os.path.join('./dogs-vs-cats/Cat/', 'cat.0.jpg')와 같이 함수에 경로들을 인자로 전달하면,
'./dogs-vs-cats/Cat/cat.0.jpg'와 같이 전체 경로를 반환합니다. - sorted: 데이터를 정렬된 리스트로 만들어서 반환합니다.
2. images_filepaths = [*cat_images_filepaths, *dog_images_filepaths]
두 변수를 하나의 리스트로 합쳐줍니다.
-> ['./dogs-vs-cats/Cat/cat.0.jpg', './dogs-vs-cats/Dog/dog.0.jpg',
,'./dogs-vs-cats/Cat/cat.1.jpg', './dogs-vs-cats/Dog/dog.1.jpg']
'./dogs-vs-cats/Cat/cat.2.jpg', './dogs-vs-cats/Dog/dog.2.jpg' ....]
3. correct_images_filepaths = [i for i in images_filepaths if cv2.imread(i) is not None]
images_filepaths에 있는 파일 경로 중에서 cv2.imread() 함수가 None을 반환하지 않는 파일 경로만 모아서 리스트로 만듭니다.
이를 통해 이미지 파일이 아닌 파일 경로는 제외됩니다.
4. random.seed(42): 난수 발생기(random number generator)를 초기화합니다. 이를 초기화하는 것은 난수를 생성하는 시드(seed) 값을 고정시키는 것입니다. 이렇게 하면 같은 시드 값으로 초기화한 난수 발생기를 사용하면 항상 같은 난수를 생성할 수 있습니다. 따라서, 코드의 실행 결과를 재현하는 데 유용합니다.
기본적인 데이터셋 준비가 완료되었습니다.
이제부터 모델 학습을 위한 구체적인 단계들이 시작될 텐데 순서는 다음과 같습니다.
먼저 데이터셋에는 학습할 데이터의 경로를 정의하고 그 경로에서 데이터를 읽어 옵니다.
데이터셋 크기가 클 수 있으므로 __init__ 에서 전체 데이터를 읽어오는 것이 아니라 경로만 저장해 놓고, __getitem__ 메서드에서 이미지를 읽어 옵니다.
즉, 데이터를 어디에서 가져올지 결정합니다. 이후 데이터로더에서 데이터셋의 데이터를 메모리로 불러오는데, 한꺼번에 전체 데이터를 불러오는 것이 아니라 배치 크기만큼 분할하여 가져옵니다.
이번에 살펴볼 DogvsCatDataset() 클래스는 데이터를 불러오는 방법을 정의합니다. 이번 예제의 목적은 다수의 개와 고양이 이미지가 포함된 데이터에서 이들을 예측하는 것입니다. 따라서 레이블(정답) 이미지에서 고양이와 개가 포함될 확률을 코드로 구현합니다.
예를 들어 고양이가 있는 이미지의 레이블은 0이 되고, 개가 있는 이미지의 레이블은 1이 되도록 코드를 구현합니다.
4. 이미지 데이터셋 클래스 정의
class DogvsCatDataset(Dataset):
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list # 이미지 데이터가 위치한 파일 경로
self.transform = transform # DogvsCatDataset 클래스를 호출할 때 transform에 대한 매개변수를 받아 옵니다.
self.phase = phase # ImageTransform()에서 정의한 train과 val을 의미
def __len__(self): # images_filepaths 데이터셋의 전체 길이 반환
return len(self.file_list)
def __getitem__(self,idx): # 데이터셋에서 데이터를 가져오는 부분으로 결과는 텐서 형태
img_path = self.file_list[idx] # 이미지 데이터의 인덱스 가져오기
img = Image.open(img_path) # img_path 위치에서 이미지 데이터들을 가져옴
img_transformed = self.transform(img, self.phase) # 이미지에 'train' 전처리 적용
label = img_path.split('/')[-1].split('.')[0] ## 1 (레이블 값을 가져오기)
if label == 'dog':
label = 1
elif label == 'cat':
label = 0
return img_transformed, label # 전처리가 적용된 이미지와 레이블 반환1. 이미지 경로 "./dogs-vs-cats/Cat/cat.0.jpg" 에서 빨간색 부분인 cat을 추출하는 것
{kind=link}
즉, 이미지 데이터에 대한 레이블 값(dog, cat)을 가져옵니다.
5. 변수 값 정의
전처리에서 사용할 변수에 대한 값을 정의합니다.
# AlexNet은 깊이가 깊은 네트워크를 사용하므로 이미지 크기가 256이 아니면 폴링층 때문에
# 크기가 계속 줄어들어 오류가 발생할 수 있습니다.
size = 256
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
batch_size = 326. 이미지 데이터셋 정의
훈련과 검증 용도의 데이터셋을 정의합니다.
앞에서 정의한 DogvsCatDataset() 클래스를 이용하여 훈련, 검증, 테스트 데이터셋을 준비하고, 전처리를 적용합니다.
train_dataset = DogvsCatDataset(train_images_filepaths,
transform=ImageTransform(size,mean, std),
phase='train') # train 이미지에 train_transforms를 적용
val_dataset = DogvsCatDataset(val_images_filepaths,
transform=ImageTransform(size,mean, std),
phase='val') # val 이미지에 val_transforms를 적용
test_dataset = DogvsCatDataset(val_images_filepaths,
transform=ImageTransform(size, mean, std),
phase='val')
index = 0
print(train_dataset.__getitem__(index)[0].size()) # 훈련 데이터 train_dataset.__getitem__[0][0]의 크기(size) 출력
print(train_dataset.__getitem__(index)[1]) # 훈련 데이터의 레이블 출력훈련 데이터셋의 크기는 (3, 256, 256) 입니다.
이것은 (채널, 너비, 높이)를 의미합니다.
7. 데이터로더 정의
전처리와 함께 데이터셋을 정의했기 때문에 이제 메모리로 불러와서 훈련을 위한 준비를 합니다.
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) ## 1
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# train_dataloader와 val_dataloader를 합쳐서 표현
dataloader_dict = {'train': train_dataloader, 'val': val_dataloader}
batch_iterator = iter(train_dataloader)
inputs, label = next(batch_iterator)
print(inputs.size())
print(label)1. 데이터로더는 배치 관리를 담당합니다. 한 번에 모든 데이터를 불러오면 메모리에 부담을 줄 수 있기 때문에 데이터를 그룹으로 쪼개서 조금씩 불러옵니다.
< train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) >
- 첫 번째 파라미터: 데이터를 불러오기 위한 데이터셋
- batch_size: 한 번에 불러올 데이터 크기, 여기서는 32개씩 데이터를 불러옴
- shuffle: 데이터를 가져올 때 임의로 섞어서 가져옴
다음은 데이터로더를 이용하여 train 데이터셋을 메모리로 불러온 후 데이터셋의 크기와 레이블을 출력한 결과입니다.

데이터 관련 준비는 완료되었습니다.
이제 AlexNet 모델에 대한 네트워크를 정의합니다.
8. 모델의 네트워크 클래스
이제 데이터셋을 학습시킬 모델의 네트워크를 설계하기 위한 클래스를 생성합니다.
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) ## 1
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 2),
)
def forward(self, x: torch.Tensor):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xnn.AdaptiveAvgPool2d는 입력 텐서의 공간 차원을 동적으로 조정하여 고정된 출력 크기를 가지도록 합니다. 즉, 입력의 공간 차원을 자동으로 평균 풀링 연산을 수행하여 출력 크기를 지정된 크기로 조절합니다.
nn.AdaptiveAvgPool2d는 다음과 같은 구성 인자를 가지고 있습니다:
- output_size: 출력 텐서의 크기를 정의하는 튜플 혹은 단일 정수입니다.
이 값은 출력 크기를 (output_size, output_size)로 설정합니다.
nn.AdaptiveAvgPool2d((6, 6))는 입력 텐서의 공간 차원을 자동으로 조정하여 6x6 크기의 출력을 생성합니다.
입력 텐서의 크기가 다를 경우, nn.AdaptiveAvgPool2d는 입력을 알맞게 조정하여 원하는 출력 크기를 갖는 풀링 연산을 수행합니다.
이를 통해 nn.AdaptiveAvgPool2d는 입력의 공간적인 차원을 유연하게 조정하면서, 모델의 입력 크기를 고정된 크기로 맞추는 데 유용합니다. 예를 들어, AlexNet 모델의 경우 nn.AdaptiveAvgPool2d((6, 6))를 사용하여 출력을 6x6 크기로 맞춰줌으로써, 이후의 완전 연결 레이어에서 동일한 크기의 입력을 받을 수 있도록 합니다.
9. 모델 객체 생성
앞서 생성한 모델의 네트워크 클래스 (AlexNet)를 호출하여 model이라는 객체를 생성합니다.
model = AlexNet()
model.to(device)10. 옵티마이저 및 손실 함수 정의
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = nn.CrossEntropyLoss()11. torchsummary 라이브러리를 이용한 모델의 네트워크 구조 확인
from torchsummary import summary
summary(model, input_size=(3, 256, 256))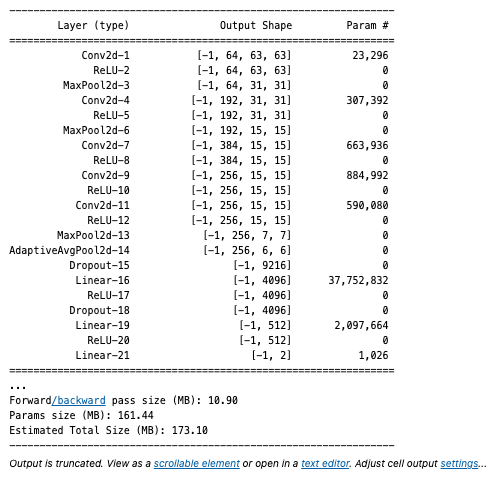
12. 모델 학습 함수 정의
def train_model(model, dataloader_dict, criterion, optimizer, num_epoch):
since = time.time()
best_acc = 0.0
for epoch in range(num_epoch):
print('Epoch {}/{}'.format(epoch + 1, num_epoch))
print('-'*20)
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 모델을 학습시키겠다는 의미
else:
model.eval()
epoch_loss = 0.0
epoch_corrects = 0
for inputs, labels in tqdm(dataloader_dict[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
epoch_loss += loss.item() * inputs.size(0)
epoch_corrects += torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(dataloader_dict[phase].dataset)
epoch_acc = epoch_corrects.double() / len(dataloader_dict[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
return model13. 모델 학습
import time
num_epoch = 10
model = train_model(model, dataloader_dict, criterion, optimizer, num_epoch)14. 모델 테스트를 위한 함수 예측
훈련 데이터셋과 더불어 테스트 데이터셋을 모델에 적용하여 정확도를 측정해 보겠습니다.
측정 결과는 데이터 프레임에 담아 둔 후 csv 파일로 저장합니다.
test 용도의 데이터셋을 이용하므로 model.eval()을 사용합니다
import pandas as pd
id_list = []
pred_list = []
_id=0
# 역전파 중 텐서들에 대한 변화도를 계산할 필요가 없음을 나타내는 것으로, 훈련 데이터셋의 모델 학습과 가장 큰 차이점입니다.
with torch.no_grad():
for test_path in tqdm(test_images_filepaths): # test 데이터셋 이용
img = Image.open(test_path)
_id =test_path.split('/')[-1].split('.')[1]
transform = ImageTransform(size, mean, std)
img = transform(img, phase='val') # test 데이터셋 전처리
img = img.unsqueeze(0) ## 1
img = img.to(device)
model.eval()
outputs = model(img)
preds = F.softmax(outputs, dim=1)[:, 1].tolist() ## 2
id_list.append(_id)
pred_list.append(preds[0])
res = pd.DataFrame({
'id': id_list,
'label': pred_list
}) # test 예측 결과인 Id와 레이블을 데이터 프레임에 저장
res.to_csv('LeNet.csv', index=False) # 데이터프레임을 csv 파일로 저장1. torch.unsqueeze는 텐서에 차원을 추가할 때 사용합니다. 또한 0은 차원이 추가될 위치를 의미합니다.
예를 들어 형태가 (3)인 텐서가 있다고 가정을 해보겠습니다. 0위치에 차원을 추가하면 형태가 (1,3)이 됩니다.
(2,2)인 텐서에서
- 0 위치에 차원 추가 → (1,2,2)
- 1 위치에 차원 추가 → (2,1,2)
- 2 위치에 차원 추가 → (2,2,1)
2. softmax는 지정된 차원을 따라 텐서의 요소가 범위에 있고 합계가 1이 되도록 크기를 다시 조정합니다.
< F.softmax(outputs, dim=1)[:, 1].tolist() >
- outputs, dim=1 : outputs에 softmax를 적용하여 각 행의 합이 1이 되도록 합니다.
- [:, 1] : 값 중 모든 행에서 두 번째 칼럼(1번째 인덱스)을 가져옵니다.
- tolist() : 배열을 리스트 형태로 변환합니다.
17. 테스트 데이터셋의 예측 결과 호출
모델 예측 함수를 실행한 결과입니다.
예측 결과를 csv 파일로 저장하는 함수였기 때문에 실행 결과는 큰 의미가 없으며 단순히 처리가 되었다고 이해하면 됩니다.
res.head(5)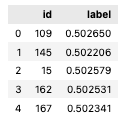
'pytorch' 카테고리의 다른 글
| [pytorch] Learning Rate Scheduler (학습률 동적 변경) (0) | 2024.05.03 |
|---|---|
| [pytorch] RNN 계층 구현하기 (0) | 2023.07.11 |
| [pytorch] 이미지 분류를 위한 LeNet-5 구현 (0) | 2023.05.15 |
| [pytorch] 전이 학습 - 특성 추출 기법 (Feature Extraction) (0) | 2023.05.09 |
| [pytorch] Convolutional Neural Network (CNN) 로 FashionMNIST 구현해보기 (0) | 2023.04.28 |