728x90
반응형
# 데이터 전처리
기본 데이터 전처리 사항
- 결손값 / 문자열 값 처리
- 이상치 제거
- 피처 선택
데이터 인코딩
- 레이블 인코딩
- 원-핫 인코딩
피처 스케일링
- StandardScaler
- MinMaxScaler
# 결측값
-Null값이 얼마 되지 않는다면=> 피처의 평균값, 중앙값, 최빈값 같은 값 넣기
-Null값이 대부분 => 해당 피처 drop
만약 중요도가 높은 피처이고, Null을 피처의 평균값으로 대체할 경우 예측 왜곡이 심할 수 있다면 더 정밀한 대체 값을 선정해야 함
사이킷런의 머신러닝 알고리즘은 문자열 값을 입력 값으로 허용X => 모든 문자열(카테코리형, 텍스트형) 값을 인코딩해서 숫자형으로 변환필수
# 데이터 인코딩 : 레이블 인코딩(label encoding) / 원-핫 인코딩(one hot encoding)
1. 레이블 인코딩(label encoding) : 문자열 값=> 숫자형 카테고리 값으로 변환
from sklearn.preprocessing import LabelEncoder
items= ['TV','냉장고','전자레인지','컴퓨터','선풍기','믹서','믹서']
#LabelEncoder를 객체로 생성한 후, fit(),transform()으로 레이블 인코딩 수행
encoder= LabelEncoder()
encoder.fit(items)
labels=encoder.transform(items)
print('인코딩 반환값:',labels)인코딩 반환값: [0 1 4 5 3 2 2]
print('인코딩 클래스:',encoder.classes_)인코딩 클래스: ['TV' '냉장고' '믹서' '선풍기' '전자레인지' '컴퓨터']TV=>0
냉장고=>1
믹서=>2
선풍기=>3
전자레인지=>4
컴퓨터=>5
문제점 : 예측 성능이 떨어지는 경우가 발생할 수 있음. 숫자 값의 경우 크고 작음에 대한 특성이 작용하기 때문
ex) 냉장고-1, 믹서-2 일 경우 1 보다 2가 더 큰 값이므로 특정 ML알고리즘에서 가중치가 더 부여되거나 더 중요하게 인식할 가능성 발생함
즉 레이블 인코딩은 선형회귀와 같은 ML알고리즘에는 적용 X , 트리 계열의 ML알고리즘은 숫자의 이러한 특성을 반영하지 않으므로 상관이 없다.
2. 원-핫 인코딩(one hot encoding) : 행 형태의 피처값을 열 형태로 차원을 변경한 후, 교유 값에 해당하는 칼럼에만 1표시, 나머지 칼럼에는 0을 표시함
-원-핫 인코딩은 사이킷런에서 OnehotEncoder 클래스로 쉽게 변환 가능
# 주의할 점
1. OnehotEncoder로 변환하기 전에 모든 문자열 값을 숫자형 값으로 변환하기
2. 입력 값으로 2차원 데이터 필요
from sklearn.preprocessing import OneHotEncoder
items= ['TV','냉장고','전자레인지','컴퓨터','선풍기','믹서','믹서']
#먼저 숫자값으로 변환하기 위해 LabelEncoder로 변환
encoder= LabelEncoder()
encoder.fit(items)
labels=encoder.transform(items)
#2차원 데이터로 변환
labels= labels.reshape(-1,1)
#원-핫 인코딩 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels=oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터차원')
print(oh_labels.shape)원-핫 인코딩 데이터
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]]
원-핫 인코딩 데이터차원
(7, 6)# 원-핫 인코딩을 지원하는 API => get_dummies()
get_dummies() 를 이용하면 숫자형 값으로 변환 없이도 바로 변환이 가능
import pandas as pd
df= pd.DataFrame({'item':['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']})
pd.get_dummies(df)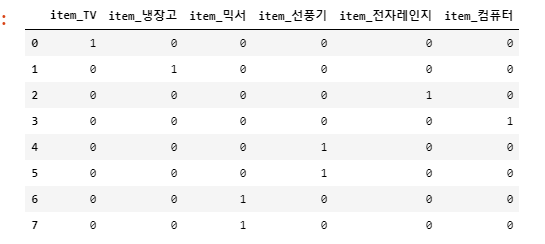
728x90
반응형
'pythonML' 카테고리의 다른 글
| [pythonML] 머신러닝으로 타이타닉 생존자 예측 (0) | 2022.03.19 |
|---|---|
| [pythonML] feature scaling(피처 스케일링) -표준화(StandardScaler)/ 정규화 (MinMaxScaler)/RobustScaler/ MinMaxScaler (0) | 2022.03.05 |
| [pythonML] cross_val_score(교차검증)/ GridSearchCV(교차검증, 최적 하이퍼 파라미터 튜닝) (0) | 2022.03.02 |
| [pythonML] K-fold / stratifiedKFold - 교차검증 (0) | 2022.03.02 |
| [pythonML] 데이터셋분리/학습/예측/평가 - 붓꽃 품종 예측 (0) | 2022.02.22 |