학습률(Learning rate)은 모델 훈련 중 가중치를 업데이트하는 속도를 결정하는 중요한 하이퍼파라미터입니다. 적절한 학습률 설정은 모델 성능에 큰 영향을 미칠 수 있습니다.
파이토치에서는 `torch.optim.lr_scheduler` 모듈을 사용하여 학습률을 동적으로 조정할 수 있습니다. 이 모듈에는 여러 가지 스케줄러가 포함되어 있어 다양한 전략으로 학습률을 조절할 수 있습니다.
1.Lambda LR
LambdaLR는 사용자가 직접 학습률 조정 로직을 정의할 수 있는 스케줄러입니다. 이 스케줄러를 사용하면, 매 에폭마다 각 파라미터 그룹의 학습률을 사용자가 정의한 함수(`lambda` 함수)에 따라 조정할 수 있습니다. 이 함수는 현재 에폭을 입력으로 받고, 학습률을 조정할 스케일링 팩터를 반환합니다.
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import transformersn_epochs = 100
model = nn.Linear(10, 5) # 모델 정의
optimizer = optim.SGD(model.parameters(), lr=100)
# 람다 함수 정의
lambda1 = lambda epoch: 0.95 ** epoch # 매 에폭마다 학습률 5% 씩 감소
# LambdaLR 스케줄러 설정
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lambda1)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step() # 스케줄러 업데이트
plt.plot(lrs)
plt.xlabel('Epoch') # x축 레이블 추가
plt.ylabel('Learning Rate') # y축 레이블 추가
plt.title('Learning Rate Decay Over Epochs') # 그래프 제목 추가
plt.show()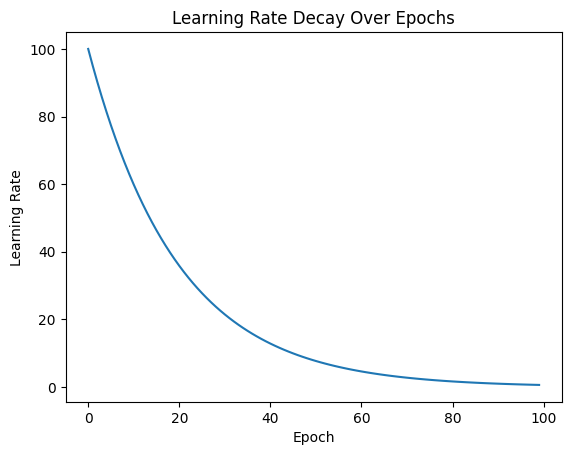
위 그림을 보면 초기 학습률이 100이고, 감소율(`decay_rate`)이 `0.95`인 경우입니다. 각 에폭마다 학습률이 `0.95`의 거듭제곱에 따라 감소하죠. 학습률 계산은 에폭 번호에 따라 이루어집니다.
첫 번째 에폭(0번째 에폭)과 두 번째 에폭(1번째 에폭)의 계산은 다음과 같습니다.
1. 첫 번째 에폭 (0번째 에폭):
- \( 0.95^{0} = 1 \)
- 학습률 = 초기 학습률 × 1 = 100 × 1 = 100
2. 두 번째 에폭 (1번째 에폭):
- \( 0.95^{1} = 0.95 \)
- 학습률 = 초기 학습률 × 0.95 = 100 × 0.95 = 95
즉, 첫 번째 에폭에서 학습률은 100으로 유지되며, 두 번째 에폭에서 학습률은 95로 감소합니다. 이런 방식으로 각 에폭마다 학습률은 `0.95`의 에폭 번호만큼의 거듭제곱으로 계속 감소하게 됩니다.
이러한 감소 패턴은 초기에 빠른 학습을 가능하게 하고, 학습이 진행됨에 따라 더 세밀한 조정을 통해 오버슈팅을 방지하고, 최적화 과정에서 안정성을 높이는 데 도움을 줍니다.
이 방식은 특히 학습 초기에 높은 학습률을 사용하여 빠르게 최적점 근처로 이동한 후, 점차 학습률을 낮추어 최적점에 더 정밀하게 수렴하고자 할 때 유용합니다.
2. Multiplicative LR
MultiplicativeLR 스케줄러는 각 에폭 후에 학습률에 일정 비율을 곱하여 학습률을 조정하는 방식입니다. 이 스케줄러는 `LambdaLR`와 유사하게 사용자가 제공한 함수를 기반으로 작동하지만, 주된 차이점은 LambdaLR은 곱셈뿐만 아니라 덧셈, 조건문, 다른 수학적 연산 등 복잡한 로직을 포함할 수 있어 매우 유연하다는 점입니다.
n_epochs = 30
model = nn.Linear(10, 5) # 모델 정의
optimizer = optim.SGD(model.parameters(), lr=100)
lambda1 = lambda epoch: 0.8
scheduler = optim.lr_scheduler.MultiplicativeLR(optimizer, lambda1)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step() # 스케줄러 업데이트
plt.plot(lrs)
plt.xlabel('Epoch') # x축 레이블 추가
plt.ylabel('Learning Rate') # y축 레이블 추가
plt.title('Learning Rate Decay Over Epochs') # 그래프 제목 추가
plt.show()
위 그림의 경우, 람다 함수 lambda1은 학습률을 에폭마다 0.8배로 곱하도록 설정되어 있습니다. 초기 학습률은 100으로 설정되어 있습니다.
에폭마다 학습률이 어떻게 변하는지 계산을 보여드리겠습니다.
1. 첫 번째 에폭 (0번째 에폭 후):
- \( \text{학습률} = 100 \times 0.8 = 80 \)
2. 두 번째 에폭 (1번째 에폭 후):
- \( \text{학습률} = 80 \times 0.8 = 64 \)
3. 세 번째 에폭 (2번째 에폭 후):
- \( \text{학습률} = 64 \times 0.8 = 51.2 \)
학습률은 처음에 100에서 시작하여, 첫 번째 에폭 후에 80으로, 두 번째 에폭 후에 64로, 그리고 세 번째 에폭 후에는 51.2로 감소합니다. 이처럼 각 에폭이 끝날 때마다 원래 학습률에 `0.8`을 곱하는 것으로 학습률이 계속 감소하게 됩니다.
3. Step LR
StepLR는 지정된 스텝 간격마다 학습률을 감소시키는 간단하면서도 효과적인 방법입니다. 이 스케줄러는 특정 에폭의 수마다 학습률을 미리 정해진 비율로 줄입니다. 이러한 방식은 학습 과정에서 중요한 지점에서만 학습률을 조정하고 싶을 때 유용합니다.
optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
주요 매개변수
- step_size: 학습률이 감소되기 전에 완료해야 하는 에폭 수입니다.
- gamma: 각 스텝마다 학습률에 곱해지는 감소율입니다. 이 값에 따라 학습률이 줄어듭니다.
n_epochs = 20
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch') # x축 레이블 추가
plt.ylabel('Learning Rate') # y축 레이블 추가
plt.title('Learning Rate Decay Over Epochs') # 그래프 제목 추가
plt.show()
초기 학습률은 `20`으로 설정합니다. 스케줄러는 `step_size=5`로 설정되어 있어, 매 5 에폭마다 학습률이 현재 값의 `50%`(gamma=0.5)로 감소합니다.

위 그림을 보면, 학습률이 5 에폭마다 절반으로 감소하는 것을 명확하게 보여줍니다. 초기 학습률은 `20`에서 시작하여 다음과 같이 감소합니다:
- 처음 5 에폭 동안 학습률은 `20`입니다.
- 6 에폭부터 10 에폭까지 학습률은 `10`입니다.
- 11 에폭부터 15 에폭까지 학습률은 `5`입니다.
- 16 에폭부터 20 에폭까지 학습률은 `2.5`입니다.
`StepLR`은 주로 균일한 간격으로 학습률을 조정해야 할 때 유용합니다. 예를 들어, 모델이 처음에 빠르게 학습하고 일정 시점 이후에 더 세밀하게 조정을 하며 최적화를 수행하고자 할 때 적합합니다. 이 스케줄러는 특히 학습 곡선이 플래토 현상을 보일 때, 즉 학습이 더 이상 개선되지 않을 때 학습률을 감소시켜 추가적인 최적화를 유도하는 데 도움을 줄 수 있습니다.
4. MultiStep LR
MultiStepLR 스케줄러는 미리 정의된 여러 개의 에폭에서 학습률을 조정합니다. 이 스케줄러는 특정 에폭들에 도달했을 때 학습률을 한 번에 감소시키는 방식으로, 단계적인 감소가 필요할 때 유용합니다. 이를 통해 모델이 처음에는 빠르게 학습을 진행하고, 중요한 시점에서 학습률을 감소시켜 더 세밀한 최적화를 가능하게 합니다.
optim.lr_scheduler.MultiStepLR(optimizer, milestones=[5, 15], gamma=0.4)
주요 매개변수
- milestones: 학습률을 감소시키기 위한 에폭 번호의 리스트입니다. 이 리스트에 지정된 에폭에 도달할 때마다 학습률이 감소합니다.
- gamma: 각 지정된 에폭에서 학습률에 곱해질 감소율입니다. 이 값에 따라 학습률이 줄어듭니다.
즉, `MultiStepLR` 스케줄러는 미리 정의된 에폭(`milestones`)에 도달했을 때 학습률을 지정된 비율(`gamma`)로 감소시킵니다.
n_epochs = 20
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[5, 15], gamma=0.4)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Decay Over Epochs')
plt.show()스케줄러는 `milestones=[5, 15]`와 `gamma=0.4`로 설정되어 있습니다. 이는 5, 15 에폭에서 현재 학습률을 0.4배로 감소시킵니다.

위 그림을 보면, 학습률이 5와 15 에폭에서 감소하는 것을 볼 수 있습니다. 특히, 초기 학습률은 20에서 시작해 다음과 같이 감소합니다:
- 0-4 에폭까지 학습률은 `20`입니다.
- 5 에폭에서 학습률은 `8`로 감소합니다 (`20 * 0.4`).
- 6-14 에폭까지 학습률은 `8`을 유지합니다.
- 15 에폭에서 학습률은 다시 `3.2`로 감소합니다 (`8 * 0.4`).
`MultiStepLR`은 대규모 데이터셋을 사용할 때 빠른 초기 진행 후, 학습이 어느 정도 진행된 후에 학습률을 크게 감소시켜 세밀한 조정을 하고자 할 때 효과적입니다. 이 방식은 특히 학습 과정에서 몇몇 중요한 시점에서만 크게 학습률을 조정하고자 할 때 적합하며, 과적합을 방지하고 모델의 일반화 성능을 향상하는 데 도움을 줄 수 있습니다.
5. Exponential LR
ExponentialLR는 매 에폭마다 학습률을 지수적으로 감소시키는 방식을 사용합니다. 이 스케줄러는 매우 단순하면서도 효과적인 방법으로, 주로 긴 학습 과정에서 학습률을 부드럽게 감소시켜 나갈 때 사용됩니다.
주요 매개변수
- gamma: 학습률 감소율로, 각 에폭마다 학습률에 곱해지는 상수입니다. 이 값이 학습률의 감소 속도를 결정합니다.
n_epochs = 20
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.4)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Decay Over Epochs')
plt.show()스케줄러는 gamma=0.4로 설정되어 있으며, 이는 각 에폭이 끝날 때마다 학습률을 원래의 40%로 줄입니다.

그래프를 통해 학습률이 매 에폭마다 급격하게 감소하는 것을 볼 수 있습니다. 초기 학습률은 20에서 시작하여 다음과 같이 감소합니다.
- 첫 에폭 후 학습률은 8이 됩니다 (20 * 0.4).
- 두 번째 에폭 후 학습률은 3.2가 됩니다 (8 * 0.4).
- 이런 식으로 계속하여 각 에폭 후 학습률은 이전 학습률의 40%로 감소합니다.
`ExponentialLR`은 복잡한 네트워크를 오랜 시간 동안 세밀하게 튜닝해야 할 경우 유용하며, 모델의 학습 초기에 비교적 높은 학습률로 시작하여 점진적으로 학습률을 줄여나가며 안정적인 수렴을 도모할 수 있습니다. 이 방법은 특히 최적화 과정에서 세밀한 조정이 필요할 때 매우 효과적입니다.
6. CosineAnnealing LR
CosineAnnealingLR는 매개변수 업데이트 시 학습률을 코사인 함수의 형태로 조절하여 주기적으로 최소값과 최댓값 사이를 오가게 합니다. 이 방식은 "Cosine Annealing" 방식으로 알려져 있으며, 학습률을 주기적으로 리셋함으로써 지역 최적점(local minima)에 갇히는 것을 방지하고 전역 최적점(global minimum)을 찾는 데 도움을 줄 수 있습니다.
optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0.01)
주요 매개변수
- T_max: 학습률이 최대값에서 최솟값으로 감소한 후 다시 최댓값으로 증가하는 데 필요한 에폭 수를 지정합니다. 이 예제에서는 T_max=10으로 설정되어 있어, 학습률은 매 10 에폭마다 초기 설정된 최대 학습률로 리셋됩니다.
- eta_min: 학습률의 최소값을 지정합니다. 이 예제에서는 eta_min=0.01로 설정되어 있으며, 각 주기의 최저점에서 학습률이 이 값에 도달하게 됩니다.
n_epochs = 100
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0.01)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Decay Over Epochs')
plt.show()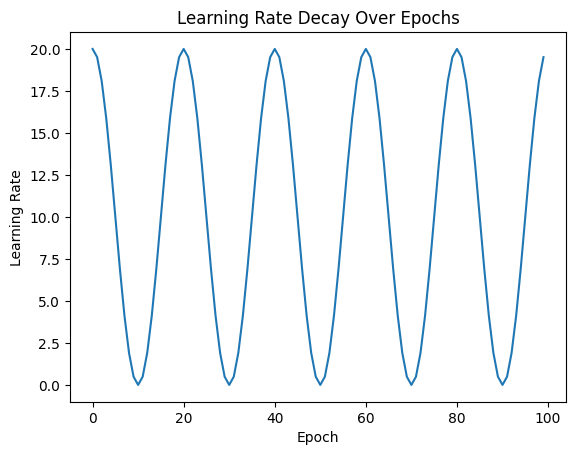
`CosineAnnealingLR`은 특히 복잡한 손실 지형에서 전역 최적점을 찾기 위한 전략으로 유용합니다. 이 스케줄러는 다양한 기계학습과 딥러닝 태스크에서 성공적으로 사용되었으며, 특히 컴퓨터 비전과 관련된 깊은 신경망 훈련에 많이 적용됩니다. Cosine Annealing은 학습 초기에는 빠른 진행을 가능하게 하고, 후반부에는 느리고 세밀한 학습을 통해 모델의 성능을 최적화합니다. 이는 특히 사전 학습된 모델을 미세 조정할 때 또는 큰 데이터셋에서 깊은 네트워크를 훈련할 때 효과적인 방법입니다.
7. ReduceLROnPlateau LR
ReduceLROnPlateau 스케줄러는 모델의 성능 향상이 정체되었을 때 학습률을 자동으로 감소시키는 방법입니다. 이 스케줄러는 모델의 검증 손실(validation loss)이 개선되지 않을 때 학습률을 감소시키는 방식으로 작동하여, 지역 최적점에 갇히는 것을 방지하고 더 좋은 전역 최적점을 찾는 데 도움을 줍니다.
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.3, patience=7)위 코드는 검증 손실이 7 에폭 동안 개선되지 않으면 학습률이 현재 값의 30%로 감소합니다.
주요 매개변수
- mode: 'min' 또는 'max'를 설정할 수 있습니다. 'min'은 손실이 감소하는 것을 기대할 때, 'max'는 정확도와 같은 다른 지표가 증가하는 것을 기대할 때 사용합니다.
- factor: 학습률을 감소시키는 비율입니다. 기본적으로 이 값은 학습률을 얼마나 줄일지 결정합니다.
- patience: 성능 향상이 멈춘 후 몇 에폭을 더 기다릴지를 설정합니다. 이 기간 동안 성능이 개선되지 않으면 학습률이 감소합니다.
- threshold: 새로운 최적의 값과 현재 값과의 차이가 이 임계값보다 작으면 개선된 것으로 간주하지 않습니다.
- cooldown: 학습률을 감소시킨 후, 다음 학습률 감소가 일어나기 전에 대기할 에폭 수입니다.
- min_lr: 학습률의 하한선입니다. 이 값 이하로 학습률이 감소하지 않습니다.
- eps: 학습률이 감소할 때 최소 변화량을 결정합니다. 이 값이 너무 작으면 학습률의 변화가 무시될 수 있습니다.
ReduceLROnPlateau는 다양한 기계학습 및 딥러닝 작업에서 효과적으로 사용될 수 있습니다. 특히, 손실이 더 이상 감소하지 않을 때 학습률을 감소시켜 모델이 세밀한 조정을 통해 더 나은 성능을 달성하도록 돕습니다. 이는 과적합을 방지하고, 긴 훈련 과정에서의 성능 저하를 막는 데 유용합니다.
8. Cyclic LR
CyclicLR 스케줄러는 학습률을 사이클 패턴(cyclical pattern)으로 변화시키는 것이 특징입니다. 이 방법은 학습률을 최솟값과 최댓값 사이에서 주기적으로 변화시켜 모델이 지역 최적점(local minima)에서 벗어나도록 돕고, 다양한 지점에서 손실 공간을 탐색하게 함으로써 전반적인 학습 성능을 향상할 수 있습니다.
scheduler = optim.lr_scheduler.CyclicLR(
optimizer,
base_lr=1e-5,
max_lr=1e-3,
step_size_up=5,
mode="triangular",
cycle_momentum=False # 모멘텀 조정 비활성화
)
주요 매개변수
- base_lr: 학습률의 최소값입니다. 사이클의 하한선으로 설정됩니다.
- max_lr: 학습률의 최대값입니다. 사이클의 상한선으로 설정됩니다.
- step_size_up: 학습률이 최소값에서 최댓값으로 증가하는 데 필요한 에폭 수입니다.
- step_size_down: 학습률이 최댓값에서 최솟값으로 감소하는 데 필요한 에폭 수입니다. 이 값을 설정하지 않으면 `step_size_up` 값과 동일하게 적용됩니다.
- mode: 학습률 변화의 모드를 설정합니다. `triangular`, `triangular2`, `exp_range` 등이 있으며, 각각 다른 변화 패턴을 제공합니다.
- scale_fn 및 scale_mode: 학습률 변화에 적용할 사용자 정의 함수와 그 모드를 지정할 수 있습니다. 이를 통해 학습률 변화 패턴을 더 세밀하게 조정할 수 있습니다.
n_epochs = 100
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.CyclicLR(
optimizer,
base_lr=1e-5,
max_lr=1e-3,
step_size_up=5,
mode="triangular",
cycle_momentum=False # 모멘텀 조정 비활성화(Adam 옵티마이저를 사용할 경우 반드시 써줘야 함)
)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Decay Over Epochs')
plt.show()

이 예제에서는 학습률이 `base_lr`인 1e-5에서 시작하여 `max_lr`인 1e-3까지 증가하고 다시 감소하는 패턴을 5 에폭마다 반복합니다. `mode='triangular'`는 가장 간단한 형태의 사이클 패턴을 제공하며, 이는 학습률을 선형적으로 증감시킵니다.
CyclicLR은 특히 빠른 학습과 함께 광범위한 학습률 탐색을 필요로 하는 경우에 유용합니다. 이 스케줄러는 다양한 영역에서 모델을 탐색하게 함으로써, 모델이 더 좋은 전역 최적점에 도달할 가능성을 높여 줍니다. 딥러닝에서는 이러한 접근 방식이 모델의 일반화 능력을 향상할 수 있으며, 특히 최적화가 어려운 복잡한 네트워크에서 유용하게 사용됩니다.
9. OneCycle LR
OneCycleLR 스케줄러는 단 한 번의 학습 사이클 동안 학습률을 먼저 증가시킨 후 감소시키는 방식으로 운영되며, 사이클의 후반부에는 학습률을 매우 낮추어 안정적인 수렴을 도모합니다. 이 스케줄러는 특히 빠른 학습과 동시에 최적의 학습률 탐색을 가능하게 하여, 모델의 성능을 극대화하고 훈련 시간을 단축시키는 효과가 있습니다.
optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, epochs=n_epochs, steps_per_epoch=10)
주요 매개변수
- max_lr: 학습률이 도달할 최대값입니다. 이 값은 학습 초기에 도달한 후 감소하기 시작합니다.
- total_steps: 전체 학습 사이클의 스텝 수입니다. 이는 전체 에폭 수와 배치 수를 곱한 값과 같을 수 있습니다. 이 값을 설정하지 않으면 `epochs`와 `steps_per_epoch`을 기반으로 계산됩니다.
- epochs: 전체 학습할 에폭 수입니다.
- steps_per_epoch: 한 에폭에서 수행할 배치의 수입니다.
- pct_start: 학습률이 증가하는 사이클의 비율입니다. 예를 들어 `0.3`은 전체 사이클의 30% 동안 학습률이 증가한다는 의미입니다.
- anneal_strategy: 학습률 감소 전략입니다. 'cos'는 코사인 감소, 'linear'는 선형 감소를 의미합니다.
- div_factor: `max_lr`을 나누어 초기 학습률을 결정합니다. 예를 들어, `max_lr`이 0.1이고 `div_factor`가 10이면, 초기 학습률은 0.01이 됩니다.
- final_div_factor: 사이클의 마지막에서 `max_lr`을 나누는 값으로, 학습률의 최종 최솟값을 결정합니다.
n_epochs = 100
model = nn.Linear(10, 5)
optimizer = optim.SGD(model.parameters(), lr=20)
scheduler = optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, epochs=n_epochs, steps_per_epoch=10)
lrs = []
for i in range(n_epochs):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Decay Over Epochs')
plt.show()

OneCycleLR은 빠른 수렴을 위해 초기에는 학습률을 급격히 증가시키고, 이후에는 점진적으로 감소시키는 전략을 사용합니다. 이러한 접근 방식은 다양한 딥러닝 모델의 훈련에서 매우 효과적이며, 특히
10. CosineAnnealingWarmRestarts LR
CosineAnnealingWarmRestarts 스케줄러는 여러 "사이클" 동안 학습률을 조절하여 재시작하는 코사인 감소 방식을 사용합니다. 이 스케줄러는 주기적으로 학습률을 리셋하고, 각 사이클의 시작에서 최대 학습률로 재시작하여 점차 최솟값으로 감소시키는 패턴을 반복합니다. 이 방식은 모델이 지역 최적점에 갇히는 것을 방지하고 다양한 지점에서의 탐색을 가능하게 하여 전역 최적점을 찾을 확률을 높여줍니다.
optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
주요 매개변수
- T_0: 첫 번째 사이클의 에폭 수입니다. 이 기간 동안 학습률은 최대에서 최소로 감소합니다.
- T_mult: 사이클 길이를 증가시키는 계수입니다. 각 사이클 후 사이클 길이는 이 계수에 따라 증가합니다.
- eta_min: 학습률의 최소값으로, 각 사이클의 최저점에서의 학습률 값으로 설정됩니다.
- last_epoch: 마지막 에폭 번호입니다. 일반적으로 학습을 재개할 때 사용됩니다.
# 모델 생성
INPUT_SIZE = 64
model = SimpleCNN().to(device)
# 옵티마이저 및 손실 함수 정의
optimizer = optim.Adam(model.parameters(), lr=CFG['LEARNING_RATE'])
criterion = nn.CrossEntropyLoss()
# 스케줄러 초기화
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
# 학습 및 평가 루프
for epoch in range(CFG['EPOCHS']):
train_loss, train_accuracy = train(model, train_loader, optimizer, criterion, device)
val_loss, val_accuracy = validate(model, val_loader, criterion, device)
# 에폭이 끝날 때마다 학습률 업데이트
scheduler.step()
print(f"Epoch {epoch+1}/{CFG['EPOCHS']} - Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}")

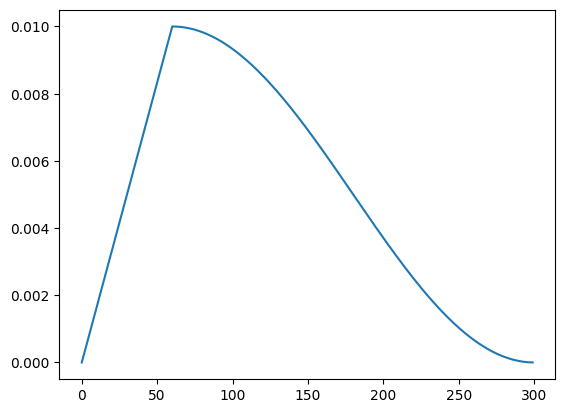
위 그림에서는 첫 사이클을 10 에폭 동안 진행한 후, 다음 사이클은 이전 사이클 길이의 두 배인 20 에폭 동안 진행합니다.
`CosineAnnealingWarmRestarts` 스케줄러는 특히 네트워크가 다양한 지역 최적점에서 탈출하여 더 광범위한 탐색을 할 수 있도록 돕는 데 유용합니다. 이 방법은 딥러닝에서 널리 사용되며, 특히 복잡하고 깊은 아키텍처에서 효과적입니다. 학습 과정을 다양화하여 모델의 일반화 능력을 향상할 수 있으며, 과적합을 방지하는 데도 도움이 됩니다.
11. get_cosine_schedule_with_warmup
get_cosine_schedule_with_warmup은 Hugging Face의 Transformers 라이브러리에서 제공하는 학습률 스케줄러 중 하나로, 특히 자연어 처리 모델을 훈련할 때 널리 사용됩니다. 이 스케줄러는 두 부분으로 구성되어 있습니다: 초기 "웜업(warmup)" 기간 동안 학습률을 점차 증가시킨 후, 이어서 코사인 감쇠(Cosine Decay) 단계에서 학습률을 점차 감소시키는 방식입니다.
이 스케줄러는 주로 트랜스포머 기반 모델을 훈련할 때 사용되며, 초기에는 모델이 데이터와 학습 방법에 적응하도록 돕고, 이후에는 성능을 최적화하면서 안정적으로 수렴하도록 도와줍니다. 이는 특히 BERT나 GPT와 같은 모델에서 매우 효과적인 학습률 조정 방법으로 입증되었습니다.
transformers.get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_total_steps)
주요 특징 및 매개변수
- warmup_steps: 이 매개변수는 학습률이 0에서 시작하여 설정된 최대 학습률까지 선형으로 증가하는 웜업 기간의 스텝 수를 정의합니다. 웜업 기간 동안 학습률이 점차 증가하며, 이는 모델이 처음부터 높은 학습률에 의해 발생할 수 있는 학습 불안정성을 방지합니다.
- total_steps: 전체 학습 동안의 스텝 수로, 이 값은 학습률이 웜업을 마치고 난 후 감소하기 시작하는 기점을 결정합니다. `total_steps`에 도달하면 학습률이 최소값에 도달합니다.
- num_cycles (선택적): 코사인 감쇠 부분을 반복할 사이클의 수를 정의합니다. 기본적으로 0.5로 설정되어 있어, 코사인 함수의 반주기만 사용합니다.
- last_epoch: 마지막 에폭 번호를 기록합니다. 이는 스케줄러가 이어지는 학습에서 어디서부터 시작해야 하는지 결정하는 데 사용됩니다.
import transformers
total_samples = 968
bs = 32
n_epochs = 10
num_warmup_steps = (total_samples // bs) * 2
num_total_steps = (total_samples // bs) * n_epochs
# 모델 생성
INPUT_SIZE = 64
model = SimpleCNN().to(device)
# 옵티마이저 및 손실 함수 정의
optimizer = optim.Adam(model.parameters(), lr=CFG['LEARNING_RATE'])
criterion = nn.CrossEntropyLoss()
# 스케줄러 초기화
scheduler = transformers.get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_total_steps)
# 학습 및 평가 루프
for epoch in range(CFG['EPOCHS']):
train_loss, train_accuracy = train(model, train_loader, optimizer, criterion, device)
val_loss, val_accuracy = validate(model, val_loader, criterion, device)
# 에폭이 끝날 때마다 학습률 업데이트
scheduler.step()
print(f"Epoch {epoch+1}/{CFG['EPOCHS']} - Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}")
Reference
Learning Rate Schedulers
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
다양한 Learning Rate Scheduler(pytorch)
월간 데이콘 제 2회 컴퓨터 비전 학습 경진대회
dacon.io
'pytorch' 카테고리의 다른 글
| [pytorch] 순환 신경망(Recurrent neural network, RNN) 이란? / RNN을 Pytorch로 구현 실습 코드 (0) | 2024.09.24 |
|---|---|
| [pytorch] 과적합 방지를 위한 가중치 규제(Weight Regularization)(feat. L1 라쏘 규제, L2 릿지 규제) (0) | 2024.05.13 |
| [pytorch] RNN 계층 구현하기 (0) | 2023.07.11 |
| [pytorch] 이미지 분류를 위한 AlexNet 구현 (6) | 2023.05.31 |
| [pytorch] 이미지 분류를 위한 LeNet-5 구현 (0) | 2023.05.15 |