728x90
반응형
# 평가 지표
-회귀
- 평균 오차
-분류
- 정확도
- 오차행렬
- 정밀도
- 재현율
- F1스코어
- ROC AUC
1. 정확도(Accuracy)
정확도(Accuracy) = 예측 결과가 동일한 데이터 건수 / 전체 예측 데이터 건수
불균형한 레이블 값 분포에서는 "정확도만으로" 성능 수치를 사용해서는 안되고 여러가지 분류지표와 함께 적용해야한다.
# 타이타닉 정확도
- 타이타닉 데이터 전처리
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
# 레이블 인코딩 수행.
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
- 단순히 sex가 1이면 0으로 / 0이면 1로 생존을 설정한 함수 (정확도의 문제점이 무엇인지 파악하기 위해)
import numpy as np
from sklearn.base import BaseEstimator
class MyDummyClassifier(BaseEstimator):
def fit(self , X , y=None): # fit( ) 메소드는 아무것도 학습하지 않음.
pass
# predict( ) 메소드는 단순히 Sex feature가 1 이면 0 , 그렇지 않으면 1 로 예측함.
def predict(self, X):
pred = np.zeros( ( X.shape[0] , 1))
for i in range (X.shape[0]) :
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else :
pred[i] = 1
return pred
- 타이타닉 생존자 예측 수행
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 원본 데이터를 재로딩, 데이터 가공, 학습데이터/테스트 데이터 분할.
titanic_df = pd.read_csv('./titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df= titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test=train_test_split(X_titanic_df, y_titanic_df, \
test_size=0.2, random_state=0)
# 위에서 생성한 Dummy Classifier를 이용하여 학습/예측/평가 수행.
myclf = MyDummyClassifier()
myclf.fit(X_train ,y_train)
mypredictions = myclf.predict(X_test)
print('Dummy Classifier의 정확도는: {0:.4f}'.format(accuracy_score(y_test , mypredictions)))Dummy Classifier의 정확도는: 0.7877단순히 sex가 1이면 0으로 / 0이면 1로 생존을 설정한 값과 정확도수치를 계산해 보았을 때
0.7877이라는 결과가 나왔다.
# mnist 정확도
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
digits = load_digits() # 사이킷런의 내장 데이터 셋 MNIST 데이터 로딩
# digits번호가 7번이면 True(1) 변환, 7번이 아니면 False(0) 변환.
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split( digits.data, y, random_state=11)
# 불균형한 레이블 데이터 분포도 확인.
print('레이블 테스트 세트 크기 :', y_test.shape)
print('테스트 세트 레이블 0 과 1의 분포도')
print(pd.Series(y_test).value_counts())
class MyFakeClassifier(BaseEstimator):
def fit(self,X,y):
pass
# 입력값으로 들어오는 X 데이터 셋의 크기만큼 모두 0값으로 만들어서 반환
def predict(self,X):
return np.zeros( (len(X),1) , dtype=bool)
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train , y_train)
fakepred = fakeclf.predict(X_test)
print('모든 예측을 0으로 하여도 정확도는:{:.3f}'.format(accuracy_score(y_test , fakepred)))
# ytest랑 0이랑 예측을 하는것 => 즉, ytest를 0으로 예측하는것레이블 테스트 세트 크기 : (450,)
테스트 세트 레이블 0 과 1의 분포도
0 405
1 45
dtype: int64
모든 예측을 0으로 하여도 정확도는:0.900
# 결론 : 정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 사용해서는 안된다. 이러한 한계점을 극복하기 위해 여러 가지 분류 지표와 함께 적용해야 한다.
2. 오차 행렬 (confusion matrix)
: 예측을 수행하면서 얼마나 헷갈리고 잇는지도 보여주는 지표
이진분류의 예측 오류가 얼마이고 어떠한 유형의 예측 오류가 발생하고 있는지 나타내는 지표
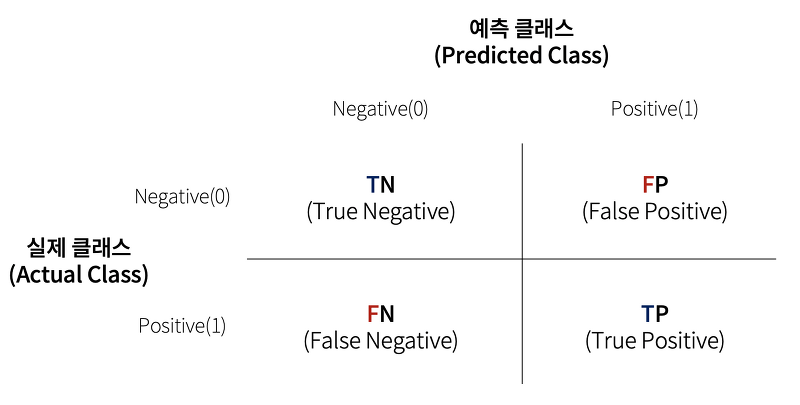
- TN => 예측값 : Negative(0) | 실제값 : Negative(0)
- FP => 예측값 : Positive(1) | 실제값 : Negative(0)
- FN => 예측값 : Negative(0) | 실제값 : Positive(1)
- TP => 예측값 : Positive(1) | 실제값 : Positive(1)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test , fakepred) # 실제결과, 예측결과array([[405, 0],
[ 45, 0]], dtype=int64)0으로 예측했을때 0인거 405
0으로 예측했을때 1인거 45
728x90
반응형
'pythonML' 카테고리의 다른 글
| [pythonML] ROC곡선과 AUC , F1스코어 - 평가 (0) | 2022.07.11 |
|---|---|
| [pythonML] 정밀도와 재현율 - 평가 (0) | 2022.07.11 |
| [pythonML] 회귀- LinearRegression (0) | 2022.05.09 |
| [pythonML] 회귀- 경사하강법 (0) | 2022.04.17 |
| [pythonML] 회귀 - 단순 선형 회귀 (0) | 2022.04.17 |