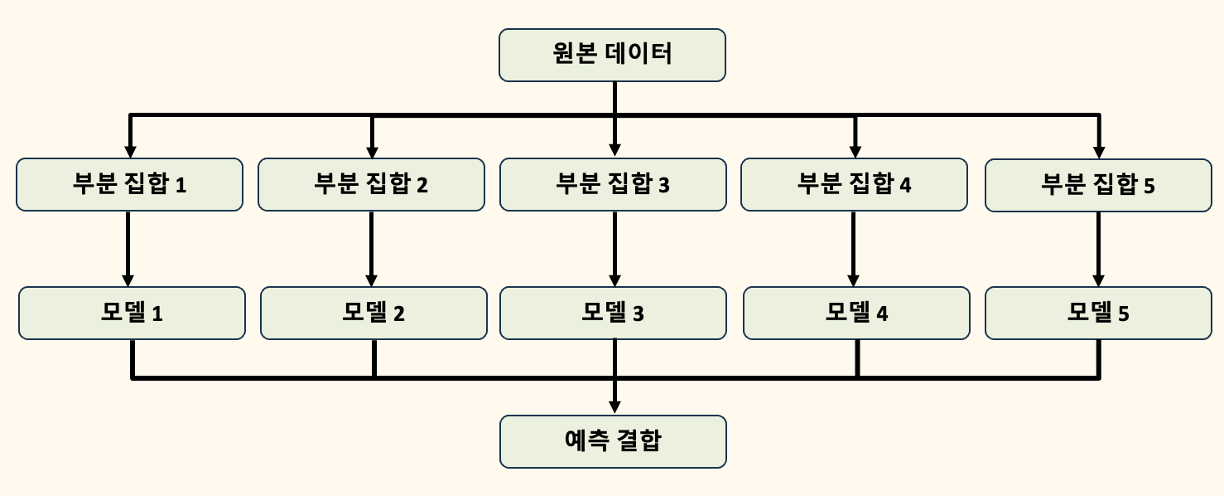
H2O란?H2O의 AutoML은 머신러닝 워크플로우를 자동화하는 데 사용될 수 있으며, 사용자가 지정한 시간 내에서 여러 모델을 자동으로 학습하고 튜닝합니다. 또한, H2O의 모델 설명 기능은 AutoML 객체 전체(즉, 여러 모델들로 구성된 모델 그룹)와 개별 모델(리더 모델 포함)에 적용할 수 있습니다. AutoML 실행 후 생성된 다양한 모델들에 대해 어떻게 작동하고 있는지, 각 모델의 예측이 어떻게 이루어졌는지 등을 설명할 수 있는 도구들을 제공합니다. AutoML 객체 자체가 앙상블 모델은 아니지만, AutoML이 생성한 앙상블 모델은 H2O의 모델 설명 기능을 통해 해석할 수 있습니다.H2O AutoML 인터페이스H2O AutoML 인터페이스는 가능한 한 적은 파라미터로 설계되어 있어, 사용자..