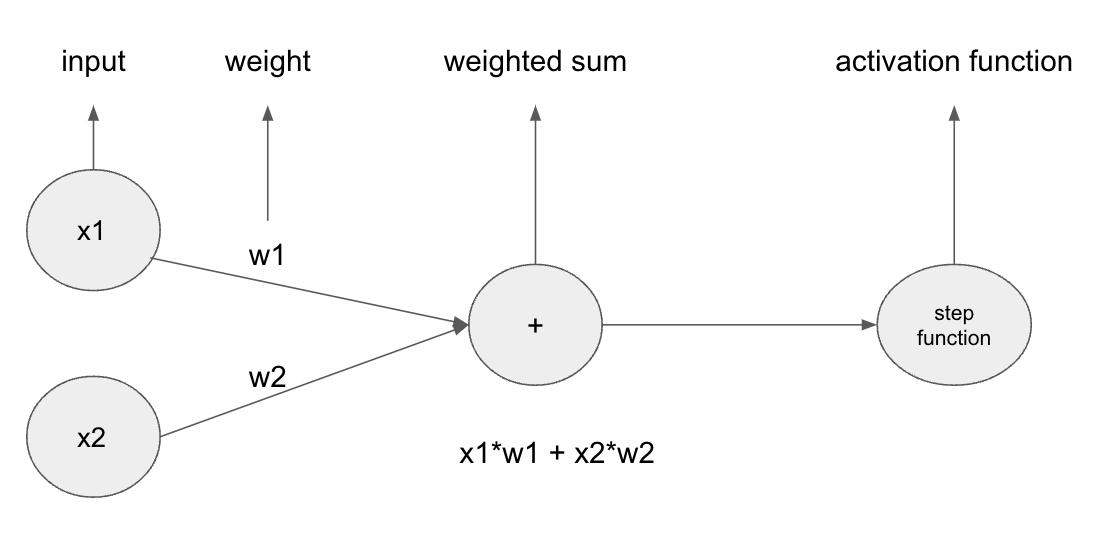
1. 입력 데이터 정규화딥러닝 모델에 입력되는 데이터는 각기 다른 범위의 값들을 포함할 수 있습니다. 예를 들어, 어떤 특성은 1에서 5 사이의 값을 가질 수 있고, 다른 특성은 1000에서 99999 사이의 값을 가질 수 있습니다. 이러한 데이터를 모델에 직접 입력하면 학습 과정에 부정적인 영향을 미칠 수 있습니다.위 이미지에서 데이터는 '몸무게'와 '키'라는 두 특성을 갖고 있어요. 몸무게의 단위는 킬로그램(kg)이며, 키의 단위는 센티미터(cm)입니다.- 왼쪽 표에서 몸무게는 60kg에서 90kg 사이고, 키는 170cm 에서 185cm 사이로 측정되어 있어요. 이러한 데이터를 기계 학습 모델에 직접 적용하면, 더 큰 숫자를 갖는 특성('키')이 모델에 더 큰 영향을 미칠 위험이 있습니다. 모델은 ..