가중치 규제(weight regularization)는 과적합(overfitting)을 방지하기 위해 신경망 모델의 학습 과정에서 가중치 크기에 제약을 추가하는 기법입니다.
과적합은 모델이 학습 데이터에는 매우 잘 맞지만, 새로운 데이터에 대해서는 일반화 성능이 떨어지는 현상을 말합니다. 가중치 규제를 사용하면 이런 문제를 어느 정도 해결할 수 있습니다.😆
가중치 규제에는 주로 두 가지 유형이 있습니다.
L1 규제 (라쏘 규제) 란? ✅
L1 규제는 모델의 손실 함수에 가중치의 절댓값의 합에 비례하는 항을 추가합니다. 수학적 표현은 다음과 같습니다.
$$ L = L_0 + \lambda \sum_{i} |w_i| $$
- \( L \): 총 손실
- \( L_0 \): 모델의 원래 손실 함수 (예: MSE, 크로스 엔트로피 등)
- \( w_i \): 모델의 가중치
- \( \lambda \): 규제의 강도를 조절하는 하이퍼파라미터
L1 규제는 일부러 가중치의 일부를 0으로 만드는 특성을 가지고 있어요. 이것은 L1 규제의 중요한 속성 중 하나로, 이를 통해 모델이 데이터의 덜 중요한 특성을 자동으로 무시하도록 합니다. 이런 효과를 흔히 "스파서티(sparcity)" 즉, 희소성을 증가시키는 것이라고 부릅니다.
L1 규제가 가중치를 0으로 만드는 이유는 수학적인 속성 때문인데요. L1 규제는 가중치의 절댓값의 합을 최소화하는 것을 목표로 합니다. 이 과정에서, 최적화 알고리즘은 비용 함수의 최솟값을 찾기 위해 일부 가중치를 정확히 0으로 설정하게 되죠. 이는 라쏘 규제의 최적화 과정에서 발생하는, 그리고 의도된 결과입니다.
가중치가 0이 된다는 것은 해당 가중치가 연결된 특성이 모델의 예측에 영향을 주지 않게 된다는 의미인데요. 결과적으로, 이 과정은 모델이 데이터의 가장 중요한 특성에만 집중하도록 도와, 모델의 복잡도를 감소시키고, 과적합을 줄이는 효과가 있어요.
실제로 이 규제 방식을 사용할 때, 데이터의 불필요하거나 노이즈가 많은 특성들이 모델에서 자동으로 제외될 수 있습니다. 이로 인해 모델이 더 간단해지고, 일반화 능력이 향상될 수 있죠. 이러한 점 때문에 L1 규제는 특히 특성의 수가 많고, 그중 일부만이 유용할 때 유리합니다.
L1 규제를 사용한 선형 회귀 모델의 가중치 갱신 방법 ✅
1. 우리가 예시로 사용할 손실함수는 MSE입니다.
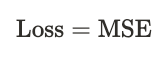
2. 손실함수 MSE에 가중치 규제를 적용하기 위해 L1 규제를 더해줍니다.

- MSE는 평균 제곱 오차입니다.
- \(\lambda\)는 규제의 강도를 나타내는 매개변수입니다.
- \(|w_j|\)는 각 가중치 \(w_j\)의 절댓값을 나타냅니다.
위 식에서 볼 수 있듯이, 가중치는 총 n개가 있습니다. 이 중 L1 규제의 특성으로 인해 일부 가중치를 0으로 만드는 특성이 바로 L1규제입니다. 예를 들어 총 10개의 가중치 중 8개의 가중치는 0에 아주 가까운 값이 되고 2개의 가중치는 0이 되어서 모델의 예측에 영향을 주지 않게 되는 거죠.
3. MSE도 수식으로 변경해 줍니다.

4. 이제 n = 1인 경우를 가정하고, 계산을 구체적으로 진행해 보겠습니다.

5. 여기서 \(\hat {y_i} = wx + b\)를 대입합니다.

6. 손실 함수를 가중치 \(w\)에 대해 미분하는 과정을 다음과 같이 진행합니다.

7. 손실 함수를 미분하면 아래와 같은 결과가 나옵니다.
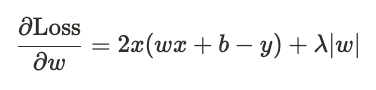
위 식에서 $|w|$는 절댓값입니다. 이 값에 대해 아래 그림과 함께 자세히 알아보도록 하겠습니다.

위 이미지는 \( y = |w| \) 함수의 그래프를 나타냅니다.
- \( y = |w| \)는 절댓값 함수로, \( w \)가 양수이면 \( y \)는 \( w \)와 같고, \( w \)가 음수이면 \( y \)는 \( -w \)가 됩니다. 이로 인해 그래프는 \( w = 0 \)을 중심으로 V자 형태를 이룹니다.
- 그래프는 \( w = 0 \)에서 \( y \) 축과 만나며, 이 지점에서 함수의 값은 0입니다.
-⭐️ 절댓값 함수의 미분 ⭐️
함수 \( y = |w| \)의 미분은 \( w \)의 값에 따라 다르게 표현됩니다.
절댓값 함수는 그 자체로 미분이 불가능한 점(여기서는 \( w = 0 \))을 제외하고는 다음과 같이 나눌 수 있습니다.
- \( w > 0 \) 일 때, \( |w| = w \)이므로, \( \frac {d}{dw}|w| = 1 \)
- \( w < 0 \) 일 때, \( |w| = -w \)이므로, \( \frac {d}{dw}|w| = -1 \)
이어서 7번에서 구한 그래디언트를 사용하여 경사하강법 또는 관련 최적화 알고리즘을 통해 \(w\)를 업데이트할 수 있습니다.
8. 가중치 갱신
가중치 \( w \)를 갱신하는 식은 다음과 같습니다

9. 7번 식을 8번 식에 대입합니다.

10. 위 식에서 "2x(wx+b−y)" 부분은 가중치 𝑤에 대한 평균 제곱 오차 손실 함수의 기울기(gradient)를 나타냅니다.
가중치 w가 양수일 때

여기서 \( \lambda \)는 양수이므로, 가중치 \( w^* \)를 감소시킵니다. 만약 \( w^* \)가 충분히 작아지면, 이러한 감소로 인해 최종적으로 0이 될 수 있습니다.
가중치 w가 음수일 때

이 경우, \( \lambda \)를 뺀 값이 \( \text {gradient} \)에 영향을 주어 \( w^* \)의 절댓값이 감소합니다. \( w^* \)의 절댓값이 감소한다는 것은 \( w^* \)가 0 방향으로 증가한다는 것을 의미합니다.
나는 개인적으로 헷갈려서 이렇게 이해했다.
식 \(w - \alpha (\text {gradient} + \lambda)\)에서 \(\text {gradient}\)를 생략하면 식은 결국 \(w - (\lambda)\)로 간소화됩니다.
여기서 \(\lambda\) 값은 항상 양수입니다.
예를 들어, \(w\)가 양수일 경우 (예: 5, 4, 3)이고 \(\lambda\)가 3이라면,
계산은 다음과 같습니다.
\(5 - 3 = 2\)
\(4 - 3 = 1\)
\(3 - 3 = 0\)
이러한 계산을 통해 \(w\)의 값이 점차 감소하여 0에 가까워지는 것을 볼 수 있습니다.
반면, \(w\)가 음수일 경우 (-5, -4, -3)이고 \(\lambda\)가 3이라면, 계산은 다음과 같습니다:
\(-5 + 3 = -2\)
\(-4 + 3 = -1\)
\(-3 + 3 = 0\)
이 경우에는 \(w\)의 값이 증가하여 점차 0에 가까워지는 것을 확인할 수 있습니다.
결국, \(w\)가 양수인 경우에는 값을 감소시켜 0에 가까워지게 하고, 음수인 경우에는 값을 증가시켜 0에 가까워지게 합니다.
L1 규제의 주요 특성과 그 효과 ✅
가중치를 0으로 유도
L1 규제는 가중치가 점차 0에 가까워지게 만듭니다. 양수인 가중치는 줄어들고, 음수인 가중치도 절댓값이 줄어들면서 0에 접근합니다. 이는 L1 규제의 주요 효과 중 하나로, 모델의 희소성을 증가시키며, 즉 많은 가중치들이 실제로 0이 되어 불필요한 특성들이 모델에서 제외됩니다.
결과적인 모델의 희소성
또한, L1 규제는 모델이 중요한 특성에만 의존하도록 하며, 불필요하거나 중요하지 않은 특성들을 제거함으로써 모델을 더 간단하고 해석하기 쉽게 만들 수 있습니다. 이러한 특성 덕분에 L1 규제는 특히 특성의 수가 많은 데이터셋에서 유용하게 사용됩니다.
L2 규제 (릿지 규제) 란? ✅
L2 규제는 모델의 손실 함수에 가중치의 제곱합에 비례하는 항을 추가하여 계산합니다. 수학적으로 표현하면 다음과 같습니다.
$$ L = L_0 + \lambda \sum_{i} w_i^2 $$
- \( L \): 총 손실
- \( L_0 \): 모델의 원래 손실 함수 (예: MSE, 크로스 엔트로피 등)
- \( w_i \): 모델의 가중치
- \( \lambda \): 규제의 강도를 조절하는 하이퍼파라미터
L2 규제는 모든 가중치를 동시에 작게 유지하려는 경향이 있어, 가중치 값들이 너무 커지지 않도록 조절합니다.
L2 규제가 가중치의 제곱합을 최소화하는 것을 목표로 하기 때문에, 최적화 과정에서 가중치의 값이 0에 가까워지기는 하지만 정확히 0이 되지는 않습니다. 이러한 특성은 모든 특성을 모델에 유지시키지만, 그 중요도에 따라 가중치의 크기를 조절하여 모델의 예측에 영향을 미치게 합니다.
L2 규제는 특히 모델이 다수의 특성을 가지고 있을 때 유용하며, 이 규제 방식은 모든 특성의 가중치를 비교적 균일하게 줄이는 효과가 있습니다. 이는 과적합을 방지하고 모델의 안정성을 높이는 데 중요한 역할을 합니다.
결과적으로, L2 규제는 데이터의 모든 특성을 고려하면서도, 가중치를 통제함으로써 모델의 일반화 능력을 향상하는 효과적인 방법을 제공합니다. 이러한 이유로 릿지 규제는 특성이 많은 데이터셋에서 널리 사용됩니다.
L2 규제를 사용한 선형 회귀 모델의 가중치 갱신 방법 ✅
1. 우리가 예시로 사용할 손실함수는 MSE입니다.

2. 손실 함수에 L2 규제를 추가하여 모델의 가중치에 제약을 적용합니다.(n=1인 경우를 가정)


여기서 \(\lambda\)는 규제 강도를 조절하는 하이퍼파라미터, \(w_i\)는 모델의 각 가중치를 의미합니다.
3. 예측 모델을 \(\hat {y} = wx + b\)라 가정하고, 가중치에 대한 손실 함수를 미분합니다.

4. 손실 함수의 미분 결과는 다음과 같습니다.

5. 위 미분 결과를 사용하여 경사 하강법을 통해 가중치 \(w\)를 갱신합니다.
가중치 w가 양수일 때
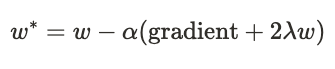
여기서 \( \lambda \)는 양수이므로, 가중치 \( w^* \)를 감소시킵니다.
가중치 w가 음수일 때

\( \lambda \)를 뺀 값이 \( \text {gradient} \)에 영향을 주어 \( w^* \)의 크기가 커집니다.
이와 같이 L2 규제는 L1과 마찬가지로, 음수인 가중치는 커져서 0에 근접하게 되고, 양수인 가중치는 작아져서 0에 근접하게 됩니다.
L2 규제의 효과 ✅
1. 가중치 축소: L2 규제는 가중치 값을 직접적으로 축소시킵니다. 가중치 \(w\)의 값이 큰 경우, 제곱이 되어 그 영향이 더욱 증가하므로, L2 규제는 큰 가중치를 강하게 제한합니다. 반대로, 작은 가중치에 대해서는 상대적으로 덜 강한 제한을 적용합니다.
2. 부드러운 규제: L2 규제는 각 가중치를 완전히 0으로 만들지 않습니다. 대신, 가중치의 크기를 점진적으로 줄여나가는 부드러운 규제 방식을 취합니다. 이는 모델의 안정성을 높이고, 데이터의 모든 특성이 일정 부분 모델에 기여할 수 있도록 합니다.
3. 과적합 방지: 큰 가중치 값은 모델이 훈련 데이터의 작은 변동성에 지나치게 반응하는 경향이 있습니다. L2 규제는 이러한 가중치의 크기를 제한함으로써 모델의 과적합을 방지하고, 일반화 성능을 향상합니다.
L1 규제 vs. L2 규제 ✅
- L1 규제는 가중치의 절댓값의 합을 규제하는 방식으로, 가중치의 값이 0이 되도록 만들어 희소한 모델을 생성합니다. 이는 특정 특성이 모델에 미치는 영향을 제거할 수 있습니다.
- L2 규제는 모든 가중치를 동시에 제한하며, 각 가중치를 완전히 0으로 만들지 않고 모든 특성의 영향을 유지하면서도 과적합을 방지합니다.
규제의 영향 ✅
규제를 사용하면 학습 과정에서 가중치가 너무 큰 값을 갖지 않도록 제한됩니다. 이는 모델이 학습 데이터의 노이즈나 불필요한 패턴에 민감하게 반응하는 것을 방지하며, 결과적으로 새로운 데이터에 대해 더 잘 일반화될 수 있도록 돕습니다.
하이퍼파라미터 \( \lambda \)는 규제의 강도를 조절하는데, 이 값이 클수록 규제의 영향이 강해지고, 작을수록 원래 모델의 복잡도를 유지하게 됩니다. 이 값의 적절한 설정은 실험을 통해 찾아내야 합니다.
이러한 규제 기법들은 신경망뿐만 아니라 다양한 머신러닝 모델에서도 사용될 수 있습니다. 특히 신경망과 같이 파라미터의 수가 많은 모델에서 규제는 매우 중요한 역할을 합니다. 모델이 더 간단하고 일반적인 패턴을 학습하도록 유도함으로써, 과적합을 방지하고 일반화 성능을 향상하는 것이 주요 목표입니다.
두 규제는 종종 함께 사용되기도 하며, 이를 L1+L2 규제 또는 엘라스틱넷 규제라고 부르기도 합니다. 신경망에서 규제는 주로 손실 함수에 규제 항을 추가하여 구현됩니다. 예를 들어, PyTorch에서 L2 규제는 간단히 옵티마이저에 weight_decay 파라미터를 설정하여 적용할 수 있습니다.
'pytorch' 카테고리의 다른 글
| [pytorch] LSTM(Long Short-Term Memory)이란? / LSTM을 Pytorch로 구현 실습 코드 (2) | 2024.09.26 |
|---|---|
| [pytorch] 순환 신경망(Recurrent neural network, RNN) 이란? / RNN을 Pytorch로 구현 실습 코드 (0) | 2024.09.24 |
| [pytorch] Learning Rate Scheduler (학습률 동적 변경) (0) | 2024.05.03 |
| [pytorch] RNN 계층 구현하기 (0) | 2023.07.11 |
| [pytorch] 이미지 분류를 위한 AlexNet 구현 (6) | 2023.05.31 |