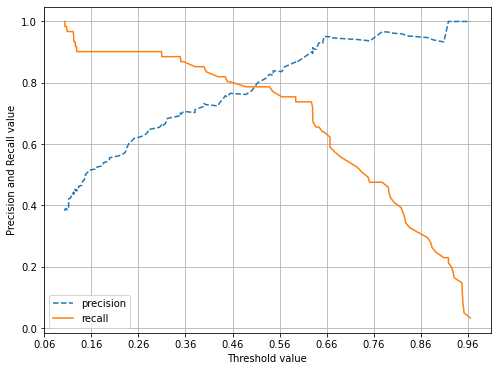
# 평가 지표 -회귀 평균 오차 -분류 정확도 오차행렬 정밀도 재현율 F1스코어 ROC AUC 4. F1 스코어 정밀도와 재현율을 결합한 지표. F1 스코어는 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가짐. ex) A : 정밀도0.9 재현율0.1 B: 정밀도 0.5 재현율 0.5 이 경우 F1 스코어는 A:0.18 / B: 0.5 로 B가 더 높다. from sklearn.metrics import f1_score f1 = f1_score(y_test , pred) print('F1 스코어: {0:.4f}'.format(f1)) F1 스코어: 0.7805 def get_clf_eval(y_test , pred): confusion = confusion_matr..