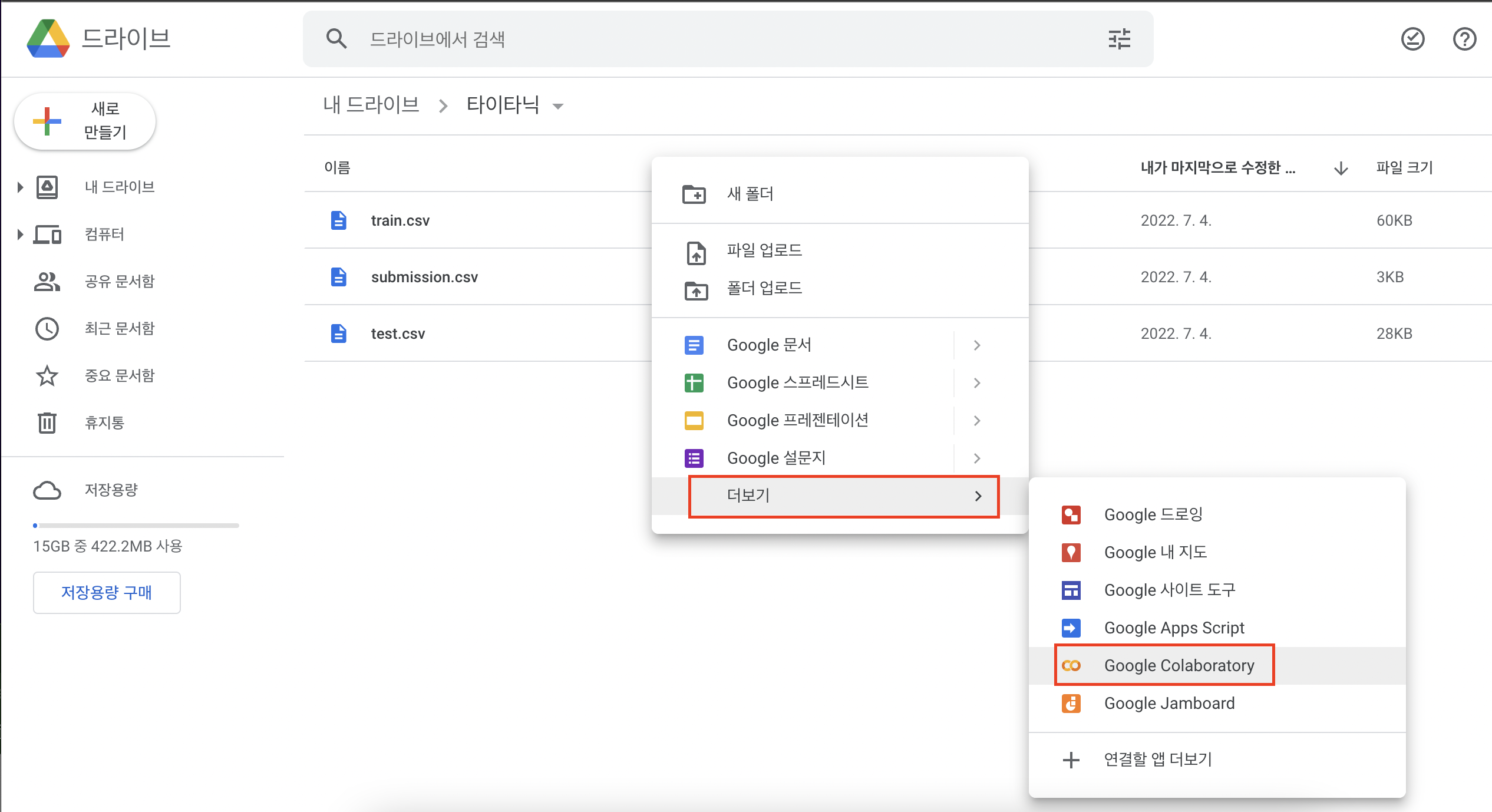
# 함수를 사용하지 않은경우 메이플스토리로 예시를 들어보자면 D_name = "듀얼블레이드" D_HP = 1000 D_MP = 200 print("{0} 캐릭터가 생성되었습니다.".format(D_name)) print("체력 {0}, 공격력 {1}".format(D_HP,D_MP)) 듀얼블레이드 캐릭터가 생성되었습니다. 체력 1000, 공격력 200 A_name = "아델" A_HP = 900 A_MP = 150 print("{0} 캐릭터가 생성되었습니다.".format(A_name)) print("체력 {0}, 공격력 {1}".format(A_HP,A_MP)) 아델 캐릭터가 생성되었습니다. 체력 900, 공격력 150 # 함수를 사용한 경우 위와 같은 코드를 함수를 이용해서 간략하게 작성을 해보면 d..