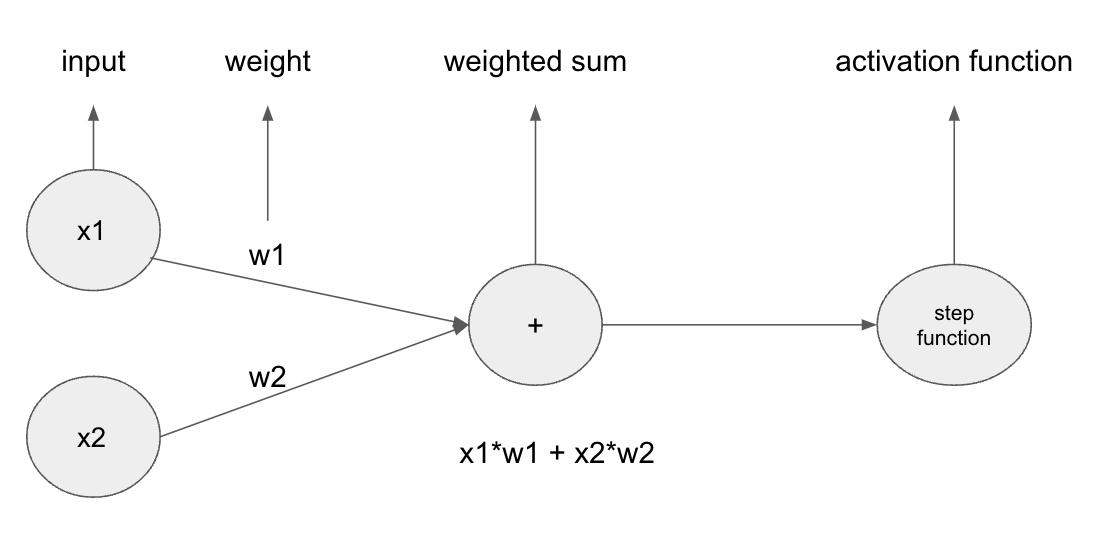
코랩으로 Mecab()을 돌려야 하는데, 자꾸 에러가 발생해서 많이 헤매다가 해결했다. 나중에 또 까먹을 것 같아서 기록하기로..! 이 포스트에서 사용된 MeCab-ko (한국어 형태소 분석기) 설치 방법은 SOMJANG님의 GitHub 저장소 'Mecab-ko-for-Google-Colab'을 참조하여 진행했습니다. 해당 저장소에는 Google Colab 환경에서 MeCab-ko를 쉽게 설치할 수 있도록 하는 스크립트가 제공됩니다. 자세한 설치 방법과 사용법은 아래 깃허브에서 확인할 수 있습니다. GitHub - SOMJANG/Mecab-ko-for-Google-Colab: Use Mecab Library(NLP Library) in Google Colab Use Mecab Library(NLP Lib..